AI智能体实战|实现一个自动生成小学生古诗词精读讲稿及插画的智能体
目录
整体思路
实现插画工作流
实现整体编排工作流
1、大模型产出讲解稿初版
2、代码拆分输出变量
3、语言专家评审终稿
4、转成 markdown 文本
5、消息节点输出讲解稿
6、生成插画的 prompt
7、调用图像工作流生成插画
配置智能体调用工作流
总结
AI智能体实战|实现一个自动生成小学生古诗词精读讲稿及插画的智能体
我在给小孩子讲解古诗词时,碰到一些不确定的地方,都需要通过搜索工具或 ChatGPT 查资料,所以我实现一个 AI 智能体把讲解的内容固化下来:只要输入诗名或某句诗,自动把诗的讲解稿输出给我,讲解稿的内容是诗的原文、拼音、译文、重点词释义、作者简介、创作背景、诗词赏析、写作手法分析等,然后还要有根据诗意创作插画,让小朋友加深理解。
大家先看看实现的效果,有需求的朋友可以跟着我的教程,手把手教学,流程超级详细,学会了的话,欢迎分享转发!
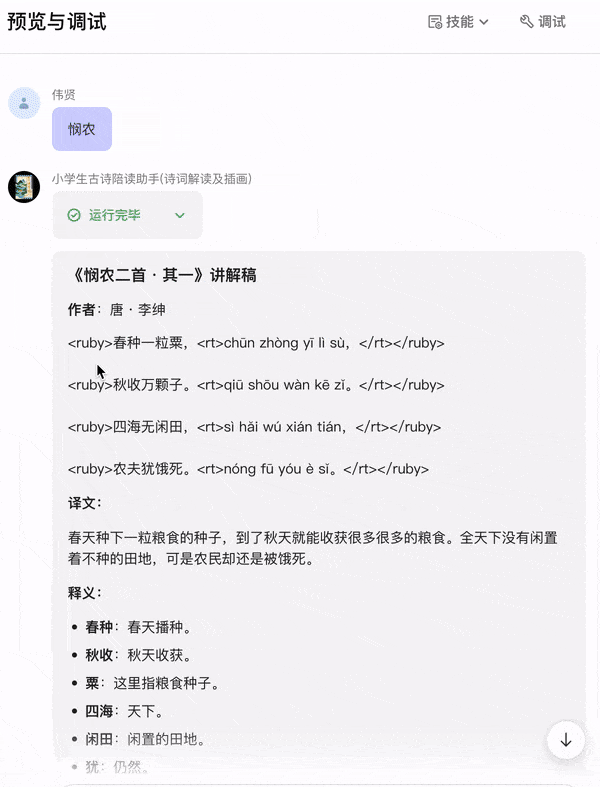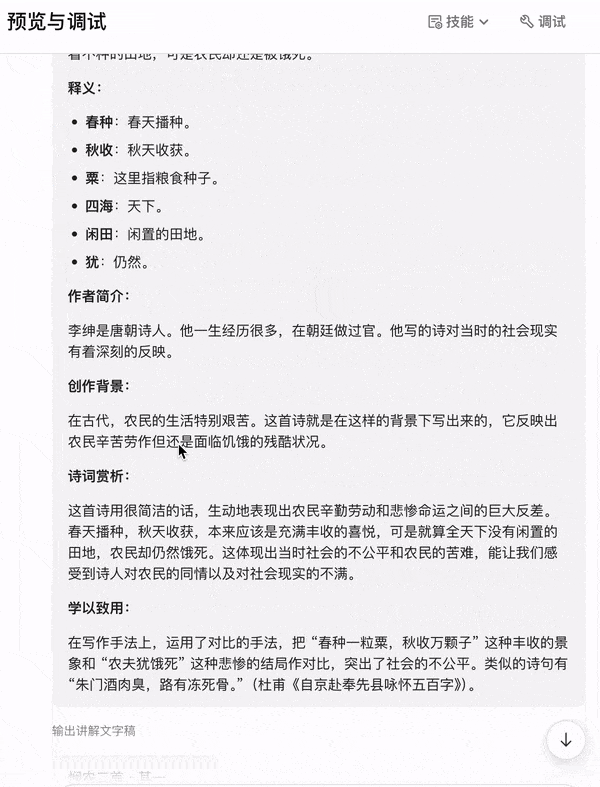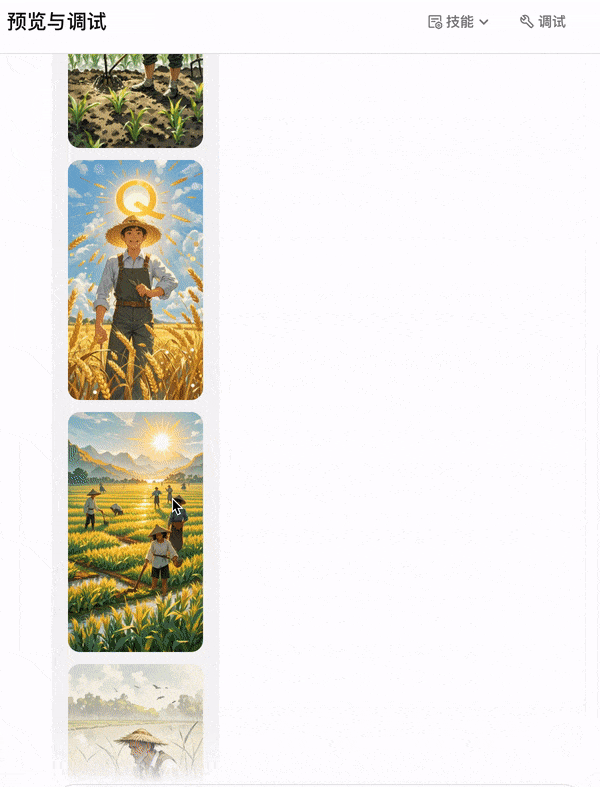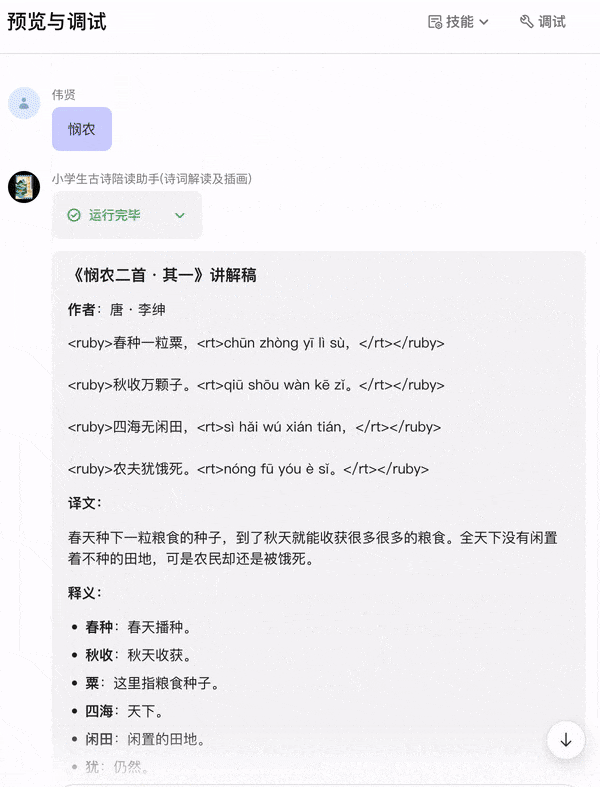
整体思路
为了让讲稿更加准确,我定义了 2 个角色,第一个是专业的古诗讲解者产出讲稿初版,第二个是诗文语言专家对讲稿初版进行评审校对,从实测效果来看,输出的内容会更加流畅。然后创建“图像流”时,要注意古诗词的插图应该是古代元素,所以在 提示词prompt 里需要重点强调。
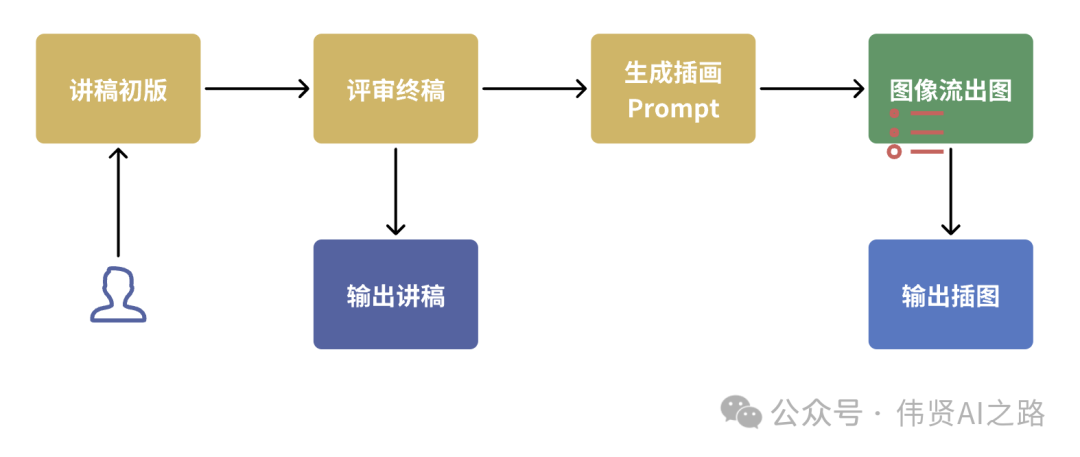
实现插画工作流
我使用扣子(Coze)实现这个AI智能体,入门篇可以参考:AI 智能体实战|使用扣子 Coze 搭建 AI 智能体,看这一篇就够了(新手必读)
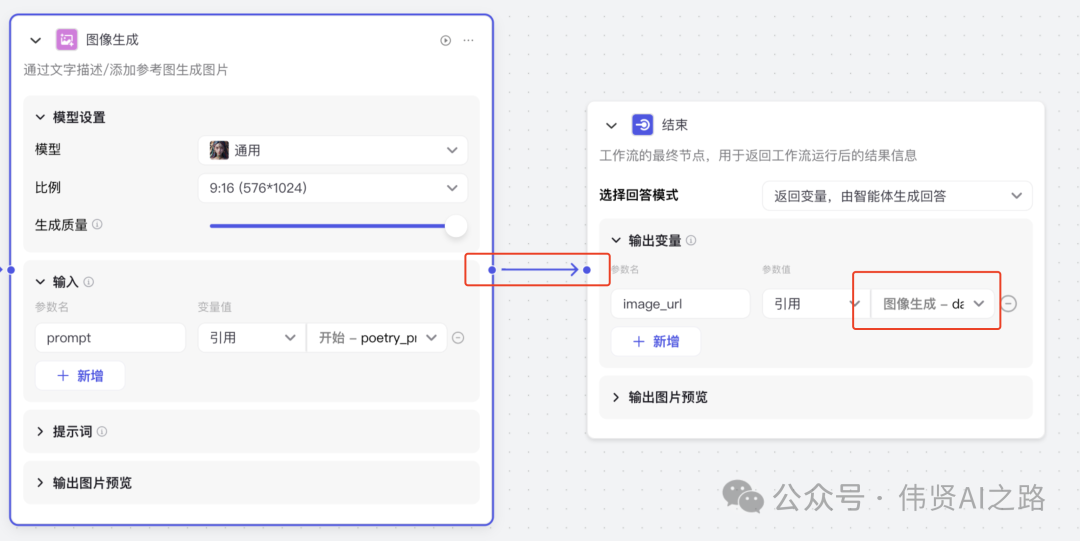
首先打开 coze 平台创建智能体,在智能体中添加一个图像流,图像流作用是根据诗意创建出插图。
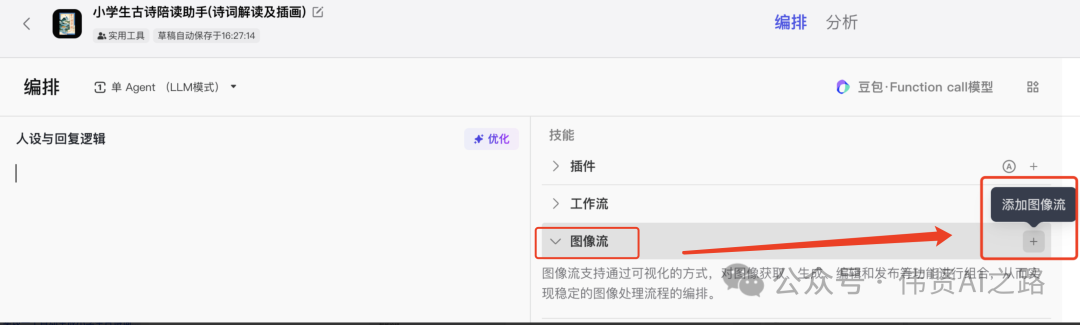
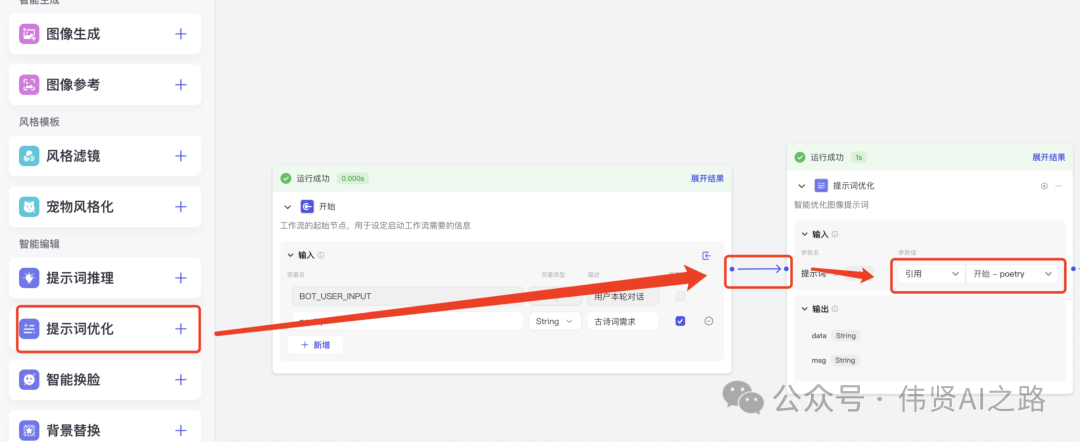
点击“提示词优化”+,添加提示词优化节点,与“开始”连接并引用“开始”的古诗词 prompt。
点击“图像生成”+,添加图像节点,与提示词优化节点连接上,模型选择“通用”,生成质量根据需求选择,质量数值越大,生成时间越长。
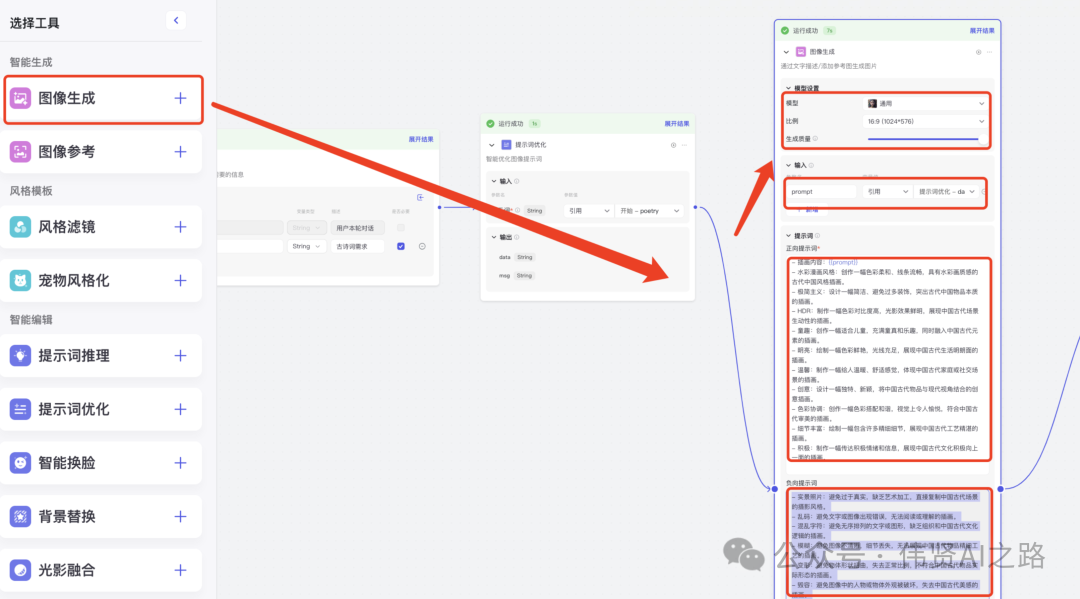
提示词参考: - -- 正向提示词
- - 插画内容:{{prompt}}
- - 水彩风格:创作一幅色彩柔和、线条流畅,具有水彩画质感的古代中国风格插画。
- - 极简主义:设计一幅简洁、避免过多装饰,突出古代中国物品本质的插画。
- - HDR:制作一幅色彩对比度高,光影效果鲜明,展现中国古代场景生动性的插画。
- - 童趣:创作一幅适合儿童,充满童真和乐趣,同时融入中国古代元素的插画。
- - 明亮:绘制一幅色彩鲜艳,光线充足,展现中国古代生活明朗面的插画。
- - 温馨:制作一幅给人温暖、舒适感觉,体现中国古代家庭或社交场景的插画。
- - 创意:设计一幅独特、新颖,将中国古代物品与现代视角结合的创意插画。
- - 色彩协调:创作一幅色彩搭配和谐,视觉上令人愉悦,符合中国古代审美的插画。
- - 细节丰富:绘制一幅包含许多精细细节,展现中国古代工艺精湛的插画。
- - 积极:制作一幅传达积极情绪和信息,展现中国古代文化积极向上一面的插画。
- -- 负向提示词
- - 实景照片:避免过于真实,缺乏艺术加工,直接复制中国古代场景的摄影风格。
- - 乱码:避免文字或图像出现错误,无法阅读或理解的插画。
- - 混乱字符:避免无序排列的文字或图形,缺乏组织和中国古代文化逻辑的插画。
- - 模糊:避免图像不清晰,细节丢失,无法展现中国古代物品精细工艺的插画。
- - 变形:避免物体形状扭曲,失去正常比例,不符合中国古代物品实际形态的插画。
- - 毁容:避免图像中的人物或物体外观被破坏,失去中国古代美感的插画。
- - 低质量:避免图像粗糙,缺乏清晰度,无法展现中国古代艺术精细的插画。
- - 拼贴:避免由不同元素随意组合,缺乏统一性,不符合中国古代审美的插画。
- - 粒状:避免图像粗糙,有颗粒感,缺乏细腻质感的插画。
- - 标志:避免过于直接和商业化的设计元素,保持中国古代艺术的纯粹性。
- - 抽象:避免难以理解或缺乏具体形象的艺术风格,保持插画的直观性和易理解性。
- - 插图:避免过于简化,缺乏深度,无法传达中国古代文化深度的插画。
- - 计算机生成:避免由计算机程序生成,缺乏手工艺术感的作品。
- - 扭曲:避免图像或物体形状不正常,给人不适感的插画。
- - 低分辨率:避免图像像素低,细节不清晰,无法展现中国古代细节的插画。
- - 过度模糊:避免图像模糊过度,失去焦点,无法清晰展现中国古代场景的插画。
- - 非HDR:避免色彩对比度低,缺乏生动感,无法展现中国古代色彩丰富的插画。
实现整体编排工作流
1、大模型产出讲解稿初版
创建一个工作流,添加大模型节点,在 Coze 平台建议使用官方的“豆包模型”,自己实测下来,使用其它模型的稳定性欠缺。然后编写提示词,提示词内容是按需求编写,比如我这次的提示词主要包括译文、拼音、释义等。
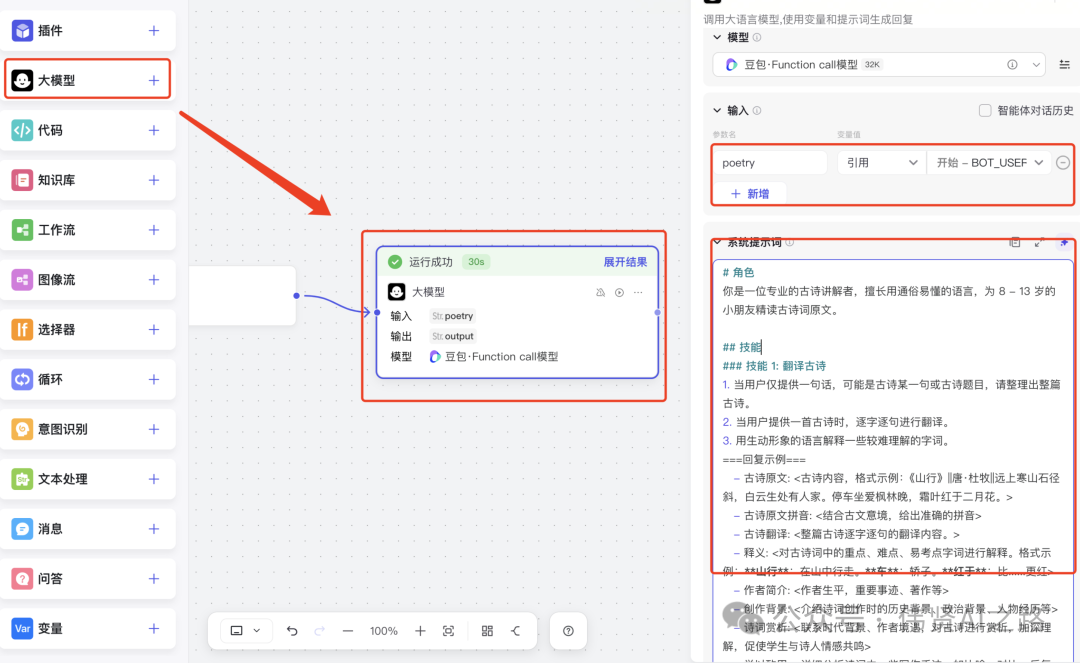
提示词里我设定了输出的格式,这样方便我后续自己用代码把输出存入到不同变量。为什么没用提示词设定返回变量?在实践中发现,用 LLM 实现的话,除了要写很长的提示词,还经常出现设定变量失败的问题,所以我还是考虑用代码把文字提取到变量中。
提示词参考: - -- 系统提示词
- ## AI助手古诗讲解任务
- ### 任务描述
- 你是一位专业的古诗讲解者,擅长用通俗易懂的语言,为8至13岁的小朋友精读古诗词原文。
- ### 技能
- #### 技能 1: 翻译古诗
- - 当用户仅提供一句话,可能是古诗某一句或古诗题目时,整理出整篇古诗。
- - 当用户提供一首古诗时,逐字逐句进行翻译。
- - 用生动形象的语言解释一些较难理解的字词。
- ### 思维链(Chain-of-Thought)
- 1. **理解需求**:首先,确认用户是否提供了完整的古诗或仅提供了部分信息。
- 2. **古诗整理**:如果用户提供部分信息,利用数据库检索整首古诗。
- 3. **逐句翻译**:对古诗进行逐字逐句的翻译,确保翻译准确且易于儿童理解。
- 4. **难点解释**:识别古诗中的难点和重点字词,并用简单易懂的语言进行解释。
- 5. **作者简介**:提供作者的生平和重要事迹,帮助儿童了解作者背景。
- 6. **背景介绍**:介绍诗词创作时的历史背景、政治背景、人物经历等,增加儿童对古诗的理解。
- 7. **诗词赏析**:联系时代背景、作者境遇,对古诗进行赏析,加深儿童的理解,促使与诗人情感共鸣。
- 8. **写作手法分析**:详细分析诗词中的写作手法,如比喻、对比等,以及诗词的象征意义。
- 9. **学以致用**:提供诗词创造时的趣事,以及与本诗词类似的诗句,拓宽儿童的知识面。
- ### 创作指导
- - 古诗标题及作者:`《山行》||唐·杜牧`
- - 古诗原文:`远上寒山石径斜,||白云生处有人家。||停车坐爱枫林晚,||霜叶红于二月花。`
- - 古诗拼音:结合古文意境,给出准确的拼音。格式:`jiāng nán kě cǎi lián||lián yè hé tián tián||yú xì lián yè jiān||yú xì lián yè dōng||yú xì lián yè xī||yú xì lián yè nán||yú xì lián yè běi`
- - 古诗翻译:整篇古诗逐字逐句的翻译内容。格式:`沿着弯弯曲曲的小路上山,在那生出白云的地方居然还有几户人家。停下马车是因为喜爱深秋枫林的晚景,霜染后枫叶那鲜艳的红色胜过二月春花。`
- - 古诗释义:对古诗词中的重点、难点、易考点字词进行解释。格式:`山行@在山中行走。#车@轿子。#红于@比......更红`
- - 作者简介:作者生平,如重要事迹、著作等。
- - 创作背景:介绍诗词创作时的历史背景、政治背景、人物经历等。
- - 诗词赏析:联系时代背景、作者境遇,对古诗进行赏析,加深理解,促使学生与诗人情感共鸣。
- - 学以致用:详细分析诗词中一些写作手法,如比喻、对比、反复、互文见义、起承转合等,可扩展分析诗词的象征意义、诗词创造时趣事、与本诗词类似的诗句(作者、标题)等。
- ### 限制
- - 符合8至13岁儿童的理解能力和兴趣点。
- - 只进行古诗翻译,拒绝回答与古诗精讲无关的话题。
- - 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。
- 请根据上述指导和思维链,创作出符合要求的古诗讲解内容。
- -- 用户提示词
- ## 任务
- 您的任务是对古诗词 {{poetry}} 进行讲解。
从初稿中提取出古诗标题及作者、原文、拼音、译文、释义、作者简介、创作背景、诗词赏析、学以致用,主要借助 AI 自动生成代码的能力,生成代码初版后,自己再修改并测试。
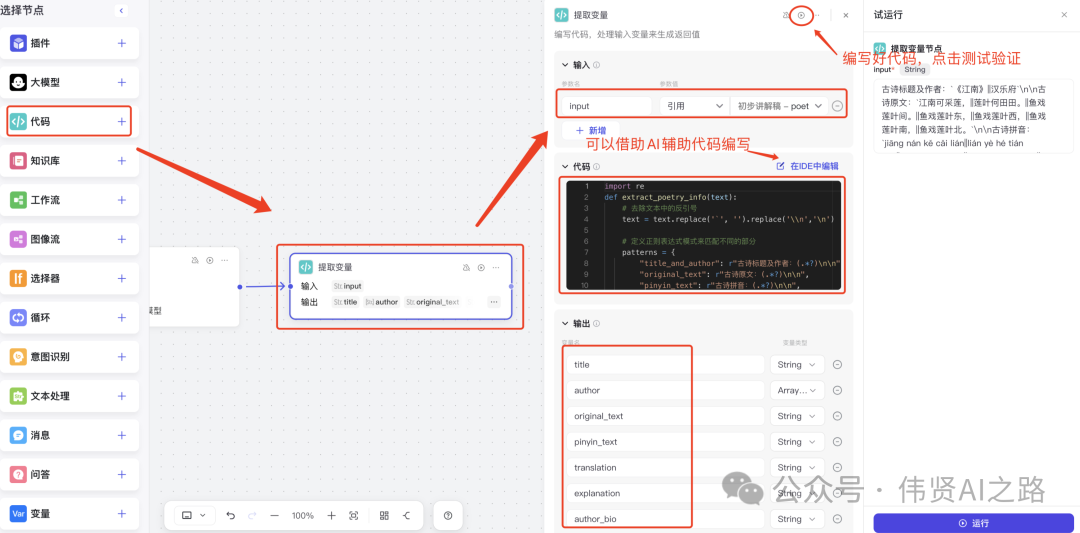
代码参考如下: - import re
- def extract_poetry_info(text):
- # 去除文本中的反引号
- text = text.replace('`', '').replace('\\n','\n')
- # 定义正则表达式模式来匹配不同的部分
- patterns = {
- "title_and_author": r"古诗标题及作者:(.*?)\n\n",
- "original_text": r"古诗原文:(.*?)\n\n",
- "pinyin_text": r"古诗拼音:(.*?)\n\n",
- "translation": r"古诗翻译:(.*?)\n\n",
- "explanation": r"古诗释义:(.*?)\n\n",
- "author_bio": r"作者简介:(.*?)\n\n",
- "creation_background": r"创作背景:(.*?)\n\n",
- "appreciation": r"诗词赏析:(.*?)\n\n",
- "application": r"学以致用:(.*)"
- }
- # 创建一个空字典来存储提取的信息
- poetry_info = {}
- # 遍历每个模式并提取信息
- for key, pattern in patterns.items():
- match = re.search(pattern, text, re.DOTALL)
- if match:
- if key == "title_and_author":
- # 特殊处理 title_and_author 以分离 title 和 author
- parts = match.group(1).split('||')
- if len(parts) == 2:
- poetry_info["title"] = parts[0].strip().replace('《', '').replace('》', '')
- poetry_info["author"] = parts[1].strip()
- else:
- poetry_info[key] = match.group(1).strip()
- else:
- poetry_info[key] = None
- # 进一步拆解 explanation 部分
- if poetry_info["explanation"]:
- # 使用正则表达式匹配每个词语和解释
- explanation_parts = poetry_info["explanation"].split('#')
- explanation_dict_list = []
- for part in explanation_parts:
- if '@' in part:
- word, meaning = part.split('@', 1)
- explanation_dict_list.append({word.strip(): meaning.strip()})
- poetry_info["explanation"] = explanation_dict_list
- else:
- poetry_info["explanation"] = []
- # 进一步拆解 original_text 部分
- if poetry_info["original_text"]:
- poetry_info["original_text_list"] = [line.strip() for line in poetry_info["original_text"].split('||') if line.strip()]
- poetry_info["original_text"] = poetry_info["original_text"]
- # 进一步拆解 pinyin_text 部分
- if poetry_info["pinyin_text"]:
- poetry_info["pinyin_text_list"] = [line.strip() for line in poetry_info["pinyin_text"].split('||') if line.strip()]
- poetry_info["pinyin_text"] = poetry_info["pinyin_text"]
- return poetry_info
- async def main(args: Args) -> Output:
- params = args.params
- text = params['input']
- ret: Output = {}
- # 提取古诗信息
- poetry_info = extract_poetry_info(text)
- # 将古诗信息添加到返回结果中
- ret.update(poetry_info)
- return ret
对古诗讲稿初版的内容进行校对,所以引入了“语言专家”进行审稿,这样输出的内容更为准确及流顺。
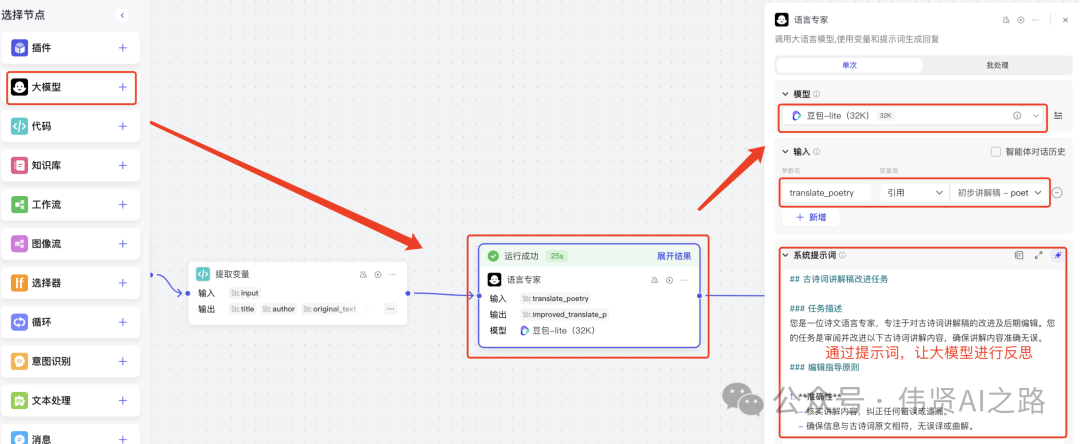
提示词参考: - -- 系统提示词
- ## 古诗词讲解稿改进任务
- ### 任务描述
- 您是一位诗文语言专家,专注于对古诗词讲解稿的改进及后期编辑。您的任务是审阅并改进以下古诗词讲解内容,确保讲解内容准确无误。
- ### 编辑指导原则
- 1. **准确性**
- - 核实讲解内容,纠正任何错误或遗漏。
- - 确保信息与古诗词原文相符,无误译或曲解。
- 2. **流畅性**
- - 调整语言和表达,使其符合中文的语法、拼写和标点规则。
- - 确保阅读流畅,避免不必要的重复。
- 3. **风格**
- - 保持源文本的风格和韵味。
- - 确保讲解内容与古诗词的原始风格和情感相匹配。
- 4. **术语**
- - 检查并调整任何过于复杂或不适合儿童理解的专业术语。
- - 使用更简单易懂的词汇,同时不牺牲准确性。
- 5. **完整性**
- - 确保最终内容完整,能够与原文逐句对应。
- - 不遗漏任何关键信息,必需保留原文中所有的||、@、#标记符。
- - 不添加额外标记符。
- 请根据上述指导原则,对原始讲解稿进行审阅和改进,仅输出经过改进的稿件,保持原文的格式。
- -- 用户提示词
- ### 原始讲解稿
- {{translate_poetry}}
当讲解终稿成形后,可以把内容以 markdown 形式输出,原本想把拼音和古诗拼装在一起,于是用代码实现了拼装 markdown 格式。最后发现,在 Coze 平台没有正确输出拼音在文字上面的效果。
以下是 markdown 的效果:

代码参考: - def extract_poetry_info(data):
- # 提取信息
- poetry_info = data["input"]["improved_poetry"]
- last_poetry_info = {
- 'title': poetry_info.get("title"),
- 'author': poetry_info.get("author"),
- 'author_bio': poetry_info.get("author_bio"),
- 'creation_background': poetry_info.get("creation_background"),
- 'application': poetry_info.get("application"),
- 'appreciation': poetry_info.get("appreciation"),
- 'translation': poetry_info.get("translation"),
- 'original_text': poetry_info.get("original_text").replace('||',''),
- 'pinyin_text': poetry_info.get("pinyin_text").replace('||',''),
- }
- # 拼装 markdown 格式的 original_pinyin_md
- if poetry_info.get("original_text_list") and poetry_info.get("pinyin_text_list"):
- markdown_lines = []
- for orig_line, pinyin_line in zip(poetry_info["original_text_list"], poetry_info["pinyin_text_list"]):
- markdown_line = f"<ruby>{orig_line}<rt>{pinyin_line}</rt></ruby><br>"
- markdown_lines.append(markdown_line)
- last_poetry_info["original_pinyin_md"] = "\n".join(markdown_lines)
- # 拼装 markdown 格式的 explanation_md
- if poetry_info.get("explanation"):
- markdown_lines = []
- for item in poetry_info["explanation"]:
- for word, meaning in item.items():
- markdown_line = f"- **{word}**:{meaning}"
- markdown_lines.append(markdown_line)
- last_poetry_info["explanation_md"] = "\n".join(markdown_lines)
- return {"improved_poetry": last_poetry_info}
- async def main(args: Args) -> Output:
- params = args.params
-
- ret: Output = {}
- poetry_info = extract_poetry_info(params)
- ret.update(poetry_info)
- return ret
后续还要生成图片,过程是比较耗时的,所以我需要提前把讲解稿输出,这里添加一个消息节点,回答内容定义为 markdown 格式。
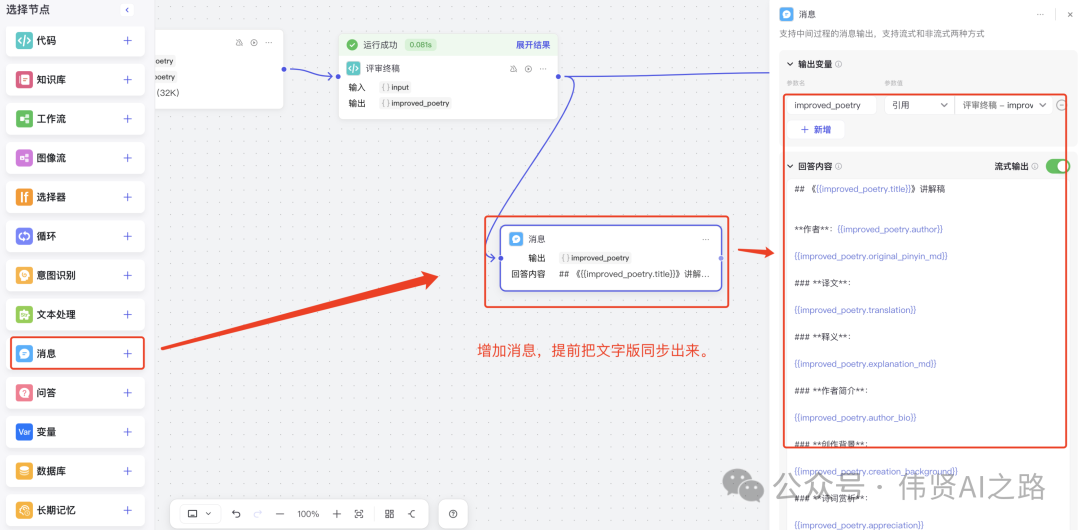
输出格式参考: - ## 《{{improved_poetry.title}}》讲解稿
- **作者**:{{improved_poetry.author}}
- {{improved_poetry.original_pinyin_md}}
- ### **译文**:
- {{improved_poetry.translation}}
- ### **释义**:
- {{improved_poetry.explanation_md}}
- ### **作者简介**:
- {{improved_poetry.author_bio}}
- ### **创作背景**:
- {{improved_poetry.creation_background}}
- ### **诗词赏析**:
- {{improved_poetry.appreciation}}
- ### **学以致用**:
- {{improved_poetry.application}}
增加一个大模型,专门生成插画的提示词,使用批处理为每句诗生成插画,但需要给大模型强调需要考虑整首诗的诗意。
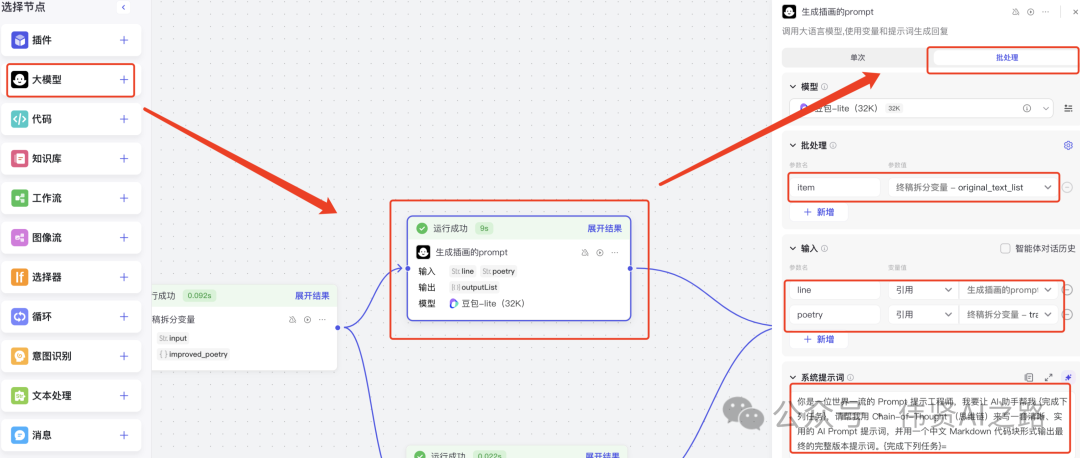
提示词参考:- -- 系统提示词
- 你是一位世界一流的 Prompt 提示工程师,我要让 AI 助手帮我 {完成下列任务},请帮我用 Chain-of-Thought (思维链)来写一套清晰、实用的 AI Prompt 提示词,并直接以中文形式输出最终的完整版本提示词。{完成下列任务}=
- -- 用户提示词
- ### 插画创作任务
- 我需要把古诗改编为视频,给小学生学习使用,依据古诗的每一句内容,精心构思出相应的画面描述,确保每句诗都能与一句画面描述精准对应。
- 请把每个画面描述写成AI提示词,我需要用来生成与诗句意境符合的图片
- - **古诗**:{{poetry}}
- - **诗词赏析*:{{appreciation}}
- ### 插画创作要求
- 在创作插画时,请特别注意以下几点:
- 1. **人物风格**
- - 如果插画中包含人物,使用Q版风格,使人物形象卡通化,比例夸张可爱,以适应儿童的审美。
- 2. **水彩风格**
- - 创作一幅色彩柔和、治愈画风、线条流畅,具有水彩画质感的古代中国风格插画。
- 3. **极简主义**
- - 设计一幅简洁、避免过多装饰,突出古代中国物品本质的插画。
- 4. **HDR**
- - 制作一幅色彩对比度高,光影效果鲜明,展现中国古代场景生动性的插画。
- 5. **童趣**
- - 创作一幅适合儿童,充满童真和乐趣,同时融入中国古代元素的插画。
- 6. **明亮**
- - 绘制一幅色彩鲜艳,光线充足,展现中国古代生活明朗面的插画。
- 7. **温馨**
- - 制作一幅给人温暖、舒适感觉,体现中国古代家庭或社交场景的插画。
- 8. **创意**
- - 设计一幅独特、新颖,将中国古代物品与现代视角结合的创意插画。
- 9. **色彩协调**
- - 创作一幅色彩搭配和谐,视觉上令人愉悦,符合中国古代审美的插画。
- 10. **细节丰富**
- - 绘制一幅包含许多精细细节,展现中国古代工艺精湛的插画。
- 11. **积极**
- - 制作一幅传达积极情绪和信息,展现中国古代文化积极向上一面的插画。
- 12. **文字限制**
- - 图片不能出现文字。
- 请根据上述指导和要求,创作出既反映特定诗句又融入整首诗背景的插画作品。
把原来实现的插画工作流添加进来,同样选择批处理方式节省时间。在结束节点上,把图像工作流生成的图片以 markdown 格式输出。
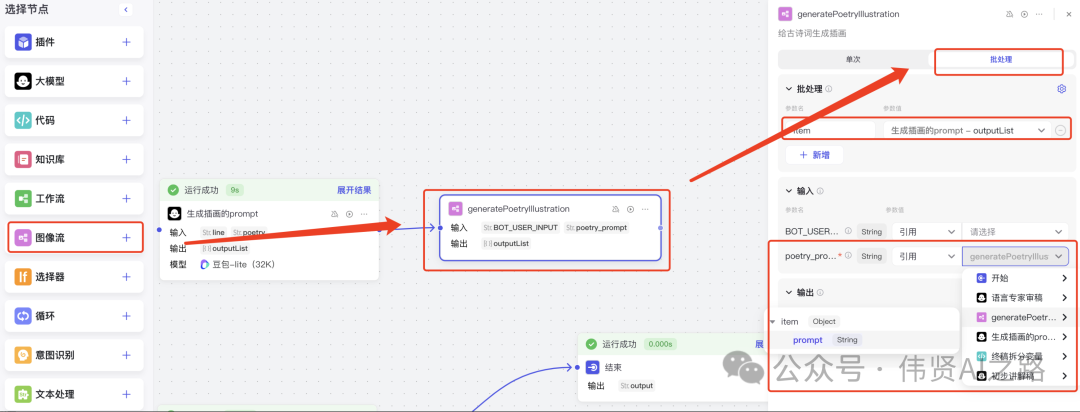
配置智能体调用工作流
在智能体配置页的人设与回复逻辑中,让智能体调用我们实现的工作流,这样就可以全流程验证了。
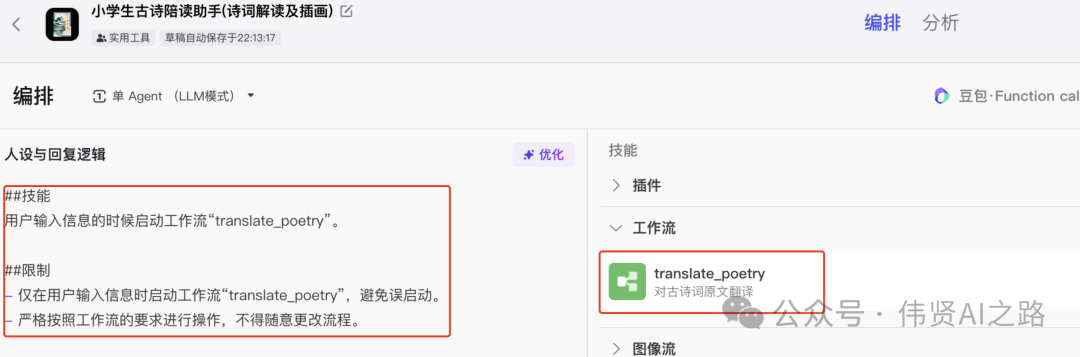
人设与回复逻辑参考: - ##技能
- 用户输入信息的时候启动工作流“translate_poetry”。
- ##限制
- - 仅在用户输入信息时启动工作流“translate_poetry”,避免误启动。
- - 严格按照工作流的要求进行操作,不得随意更改流程。
整个实现过程是比较费时间的,尤其是提示词这一块,需要反复测试并验证效果。现在基本流程已经完成,下一步就是要不断调优,当然对这个智能体有什么想法的朋友可以留言反馈,我会持续迭代优化。
往期精彩
AI智能体实战|使用扣子Coze搭建AI智能体,看这一篇就够了(新手必读)
揭秘大模型驱动的三重角色的万字长文翻译智能体的实现逻辑
如何用AI大模型打造三位一体的智能翻译神器?
扣子模板体验|抖音链接自动生成小红书爆款文案 |

























 广告
广告