作者:CSDN博客
文章目录
从零开始学习LangChain:新手入门全指南
一、什么是LangChain?
1. 核心定义2. 用类比理解LangChain3. 核心组件(3大模块)
二、为什么要用LangChain?三、安装与环境配置
1. 基础安装2. LangSmith配置(必学工具)
四、核心功能与基础用法
1. 模型调用(Models)2. 提示词模板(Prompt Templates)3. 链(Chains):组合组件4. 代理(Agents):让模型自主决策5. 向量存储与检索(VectorStores)
五、实战案例:构建RAG对话机器人六、总结与学习建议
1. 核心知识点回顾2. 新手学习路径3. 推荐资源
从零开始学习LangChain:新手入门全指南
一、什么是LangChain?
1. 核心定义
LangChain是一个开源框架,专为开发"由大语言模型(LLMs)驱动的应用"设计。简单说,它就像一个"桥梁",能让GPT-4、Claude等模型:
连接你的私有数据(如数据库、PDF文件)执行具体操作(如发邮件、调用API)组合多个功能完成复杂任务
2. 用类比理解LangChain
官方文档里有个很形象的比喻:LangChain相当于数据库领域的JDBC。
JDBC:统一不同数据库的访问接口,让开发者不用关心底层数据库类型LangChain:统一不同大模型的使用方式,同时提供连接外部系统的能力
3. 核心组件(3大模块)
LangChain的功能通过以下三个核心组件实现:
Components(组件)
给大模型提供"基础工具",包括:
LLM Wrappers:封装不同大模型的接口,让你能用统一方式调用GPT-4、Gemini等Prompt Templates:提示词模板,避免硬编码文本(比如固定格式的问题模板)Indexes:用于从文档中高效检索相关信息的索引工具
Chains(链)
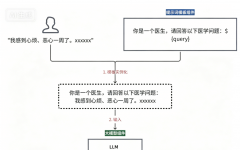
将多个组件"串联"起来完成特定任务。例如:
用Prompt Templates生成查询→调用Indexes检索文档→让LLM生成答案,这一整套流程就是一个Chain。
Agents(代理)
让大模型能"主动与外部环境交互"。比如:
当模型回答不了问题时,Agent会自动调用搜索引擎获取信息,再基于新信息生成答案。
二、为什么要用LangChain?
对于新手来说,LangChain的核心价值在于:
数据连接能力
大模型默认只能用训练时的数据,而LangChain能让模型访问你的私有数据(如本地文档、数据库)。例如:让模型读取你的PDF简历并生成求职信。
行动执行能力
不止于"回答",还能"做事"。比如:根据邮件内容自动生成待办事项并添加到日历。
简化开发流程
不用自己写复杂代码连接各种工具,LangChain已经封装好了常用功能,开箱即用。
三、安装与环境配置
1. 基础安装
首先通过pip安装核心库:- # 安装LangChain核心框架
- pip install langchain
- # 安装OpenAI集成(如果用GPT模型)
- pip install langchain-openai
LangSmith是LangChain官方的开发平台,用于调试、测试大模型应用,强烈建议新手使用。
步骤如下:
注册账号:访问 LangSmith官网,用GitHub/Google账号登录
- 获取API Key:
登录后进入Settings页面点击"Create API Key",选择"Personal Access Token"保存生成的API Key(只显示一次,丢失需重新创建)
- 环境变量配置:
- import os
- os.environ["LANGCHAIN_API_KEY"]="你的API Key"
- os.environ["LANGCHAIN_TRACING_V2"]="true"# 开启追踪功能
LangSmith的免费版包含:
1个用户每月5000次免费追踪(记录应用运行过程)基础调试和测试功能
四、核心功能与基础用法
1. 模型调用(Models)
用统一接口调用不同大模型,以OpenAI的GPT-4为例:- # 导入OpenAI模型包装器from langchain_openai import ChatOpenAI
- # 初始化模型(需要OpenAI API Key)
- os.environ["OPENAI_API_KEY"]="你的OpenAI密钥"
- model = ChatOpenAI(
- model="gpt-4",# 模型名称
- temperature=0.7# 创造性参数(0-1,值越高回答越灵活))# 调用模型生成文本
- response = model.invoke("用一句话介绍LangChain")print(response.content)
model:模型名称(如"gpt-3.5-turbo"、“gpt-4”)temperature:控制输出随机性(0=严谨,1=创造性强)
2. 提示词模板(Prompt Templates)
避免重复编写提示词,动态插入变量:- from langchain.prompts import PromptTemplate
- # 定义模板(用{变量名}作为占位符)
- template ="请将以下内容翻译成{language}:{text}"
- prompt = PromptTemplate(
- input_variables=["language","text"],# 声明变量
- template=template
- )# 生成具体提示词
- formatted_prompt = prompt.format(
- language="英语",
- text="我要去上课了,不能和你聊天了。")# 调用模型
- response = model.invoke(formatted_prompt)print(response.content)# 输出:"I have to go to class and can't chat with you."
用LLMChain将提示词模板和模型组合:- from langchain.chains import LLMChain
- # 创建链(连接提示词模板和模型)
- chain = LLMChain(prompt=prompt, llm=model)# 直接运行链(自动处理格式和调用)
- response = chain.run({"language":"法语","text":"我要去上课了,不能和你聊天了。"})print(response)# 输出法语翻译结果
Agent能让模型根据需求调用工具(如搜索引擎、计算器)。以简单数学计算为例:- # 安装必要库
- pip install langchain-tools
- from langchain.agents import initialize_agent, AgentType
- from langchain.tools import CalculatorTool
- # 初始化工具(这里用计算器工具)
- tools =[CalculatorTool()]# 创建代理
- agent = initialize_agent(
- tools,
- model,
- agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,# 常用代理类型
- verbose=True# 显示思考过程)# 让代理解决问题
- response = agent.run("3的平方加上5的立方等于多少?")print(response)# 输出:134(3²+5³=9+125=134)
基于"思考-行动-观察"循环适合需要逻辑推理的任务
5. 向量存储与检索(VectorStores)
用于处理文档数据,实现"检索增强生成(RAG)",步骤如下:
- 安装库:
- pip install langchain-chroma # 轻量级向量数据库
- pip install pypdf # 处理PDF文件
- 加载并分割文档:
- from langchain.document_loaders import PyPDFLoader
- from langchain.text_splitter import RecursiveCharacterTextSplitter
- # 加载PDF
- loader = PyPDFLoader("你的文档.pdf")
- documents = loader.load()# 分割文档(大文档拆成小块)
- text_splitter = RecursiveCharacterTextSplitter(
- chunk_size=1000,# 每块1000字符
- chunk_overlap=200# 块之间重叠200字符(保持上下文))
- splits = text_splitter.split_documents(documents)
- 存储到向量数据库:
- from langchain.embeddings import OpenAIEmbeddings
- from langchain.vectorstores import Chroma
- # 创建向量存储
- vectorstore = Chroma.from_documents(
- documents=splits,
- embedding=OpenAIEmbeddings()# 用OpenAI的嵌入模型)# 创建检索器(用于查询相关文档)
- retriever = vectorstore.as_retriever()
- 检索并生成答案:
- # 检索与问题相关的文档
- docs = retriever.get_relevant_documents("文档中关于LangChain的部分讲了什么?")# 结合文档生成答案(用链组合)from langchain.chains import RetrievalQA
- qa_chain = RetrievalQA.from_chain_type(
- llm=model,
- chain_type="stuff",# 将文档内容"填充"到提示词中
- retriever=retriever
- )
- response = qa_chain.run("文档中关于LangChain的部分讲了什么?")print(response)
五、实战案例:构建RAG对话机器人
RAG(检索增强生成)是LangChain最常用的场景,能让机器人基于特定文档回答问题。完整流程如下:
加载数据:用DocumentLoaders读取PDF、网页等内容分割文本:用TextSplitter拆分成小块(适配模型上下文窗口)嵌入存储:将文本转为向量并存入VectorStore检索相关内容:根据用户问题,用Retriever找到相关文本生成答案:让LLM结合问题和检索到的文本生成回答
代码示例(整合版):- # 1. 加载文档
- loader = PyPDFLoader("课程笔记.pdf")
- documents = loader.load()# 2. 分割文本
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
- splits = text_splitter.split_documents(documents)# 3. 存储向量
- vectorstore = Chroma.from_documents(splits, OpenAIEmbeddings())
- retriever = vectorstore.as_retriever()# 4. 创建问答链
- qa_chain = RetrievalQA.from_chain_type(
- llm=model,
- chain_type="stuff",
- retriever=retriever,
- return_source_documents=True# 返回引用的文档)# 5. 提问并获取答案
- result = qa_chain({"query":"课程中提到的LangChain核心组件有哪些?"})print("答案:", result["result"])print("引用文档:",[doc.metadata for doc in result["source_documents"]])
1. 核心知识点回顾
LangChain是连接大模型与外部系统的框架三大组件:Components(工具)、Chains(流程)、Agents(决策)关键功能:数据连接、行动执行、RAG检索增强
2. 新手学习路径
先掌握基础组件(模型调用、提示词模板、简单链)学习向量存储与RAG(最常用场景)尝试用Agent实现复杂任务(如多工具协同)用LangSmith调试和优化应用
3. 推荐资源
官方文档:LangChain Docs实战项目:从简单的PDF问答机器人开始,逐步增加功能
希望这篇指南能帮你快速入门LangChain!如果有任何问题,欢迎在评论区交流~
原文地址:https://blog.csdn.net/TTKunn/article/details/150288247 |























 广告
广告