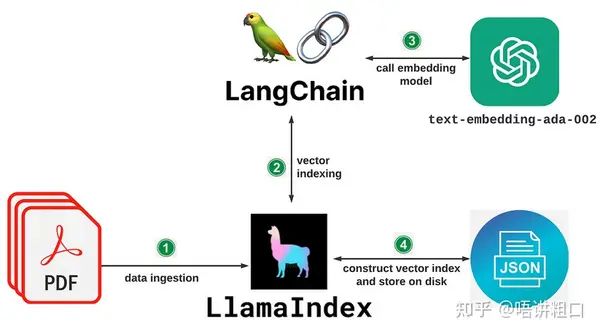
LangChain是一个基于语言模型开发应用程序的框架。它可以实现以下应用程序:





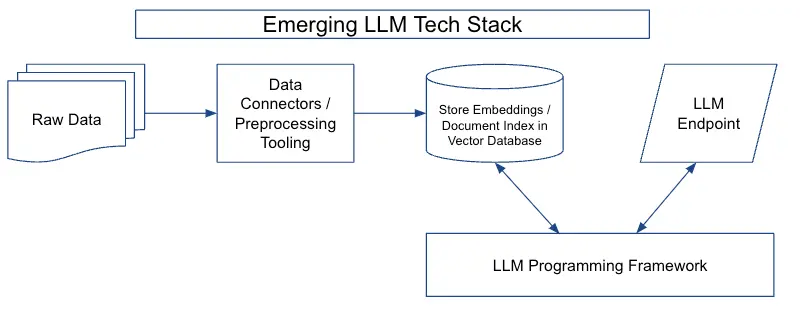
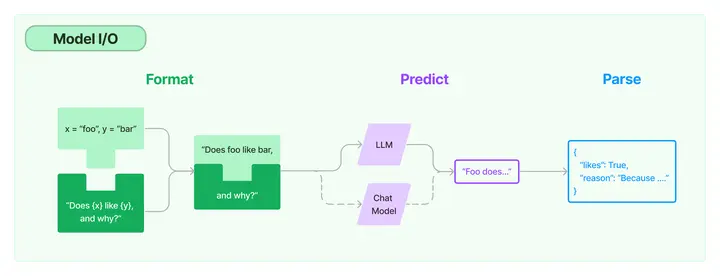
| 名称 | 语言 | 特点 |
| LangChain | Python/JS | 优点:提供了标准的内存接口和内存实现,支持自定义大模型的封装。 缺点:评估生成模型的性能比较困难。 |
| Dust.tt | Rust/TS | 优点:提供了简单易用的API,可以让开发者快速构建自己的LLM应用程序。 缺点:文档不够完善。 |
| Semantic-kernel | TypeScript | 优点:轻量级SDK,可将AI大型语言模型(LLMs)与传统编程语言集成在一起。 缺点:文档不够完善。 |
| Fixie.ai | Python | 优点:开放、免费、简单,多模态(images, audio, video...) 缺点:PaaS平台,需要在平台部署 |
| Brancher AI | Python/JS | 优点:链接所有大模型,无代码快速生成应用, Langchain产品) 缺点:- |
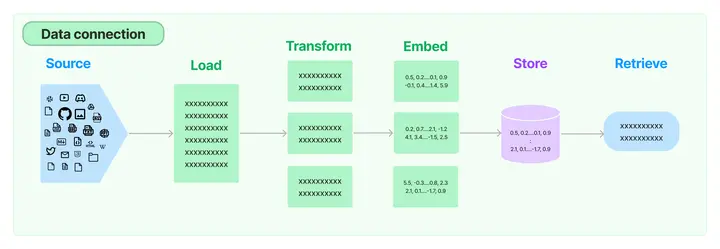
"机器学习"表示为 [1,2,3]
"深度学习"表示为[2,3,3]
"英雄联盟"表示为[9,1,3]
使用余弦相似度(余弦相似度是一种用于衡量向量之间相似度的指标,可以用于文本嵌入之间的相似度)在计算机中来判断文本之间的距离:
“机器学习”与“深度学习”的距离:
| 模型名称 | 价格 | 分词器 | 最大输入 token | 输出 |
| text-embedding-ada-002 | $0.000/1k tokens | cl100k_base | 8191 | 1536 |



| 欢迎光临 AI创想 (https://llms-ai.com/) | Powered by Discuz! X3.4 |