|
机器之心发布 机器之心编辑部 字节跳动大模型团队成果 Depth Anything V2 现已被苹果官方收入 Core ML 模型库。本文介绍了 Depth Anything 系列成果的研发历程、技术挑战与解决方法,分享了团队对于 Scaling Laws 在单一视觉任务方面的思考。值得一提的是,Depth Anything V1 与 V2 两个版本论文一作是团队实习生。 近日,字节跳动大模型团队开发的成果 Depth Anything V2 ,入选苹果公司 Core ML 模型库,目前已呈现在开发者相关页面中。
Depth Anything 是一种单目深度估计模型,V1 版本发布于 2024 年初,V2 版本发布于 2024 年 6 月,包含 25M 到 1.3B 参数的不同大小模型,可应用于视频特效、自动驾驶、3D 建模、增强现实、安全监控以及空间计算等领域。
相比上一代版本,V2 版在细节处理上更精细,鲁棒性更强,并且对比基于 Diffusion 的 SOTA 模型,速度上有显著提升。 目前 Github 上该系列成果总计收获 8.7k Star。其中,Depth Anything V2 发布不久,已有 2.3k star ,更早版本 Depth Anything V1 收获 6.4k Star。值得一提的是,Depth Anything V1 与 V2 两个版本论文一作是团队实习生。 更多模型效果,点击下方视频了解:
视频链接:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650925762&idx=2&sn=bfc32d092f417fc8bce69d4a5cf6f3c3&chksm=84e42ebcb393a7aa6dfc6900272dd537d193e1737373fa0934d9010ee043ed5248d84955db21&token=761964394&lang=zh_CN#rd 本次苹果公司收录的 Depth Anything V2 为 Core ML 版本。作为该公司的机器学习框架,Core ML 旨在将机器学习模型集成到 iOS,MacOS 等设备上高效运行,可在无互联网连接情况下,执行复杂 AI 任务,从而增强用户隐私并减少延迟。 Core ML 版本 Depth Anything V2 采用最小 25M 模型,经 HuggingFace 官方工程优化,在 iPhone 12 Pro Max 上,推理速度达到 31.1 毫秒。与其一同入选的模型还有 FastViT 、ResNet50 、YOLOv3 等,涵盖自然语言处理到图像识别多个领域。 相关论文与更多效果展示:
一、Scaling Laws 对单一视觉任务的启示 随着近两年大模型潮涌,Scaling Laws 的价值也被越来越多人认同。身处其中,有的研究团队致力于研发一个模型,以实现目标检测、图像分割等多种视觉任务,Depth Anything 团队选择了另一个方向—— 依托 Scaling Laws 思路,构建一个简单但功能强大的基础模型,在单一任务上实现更好效果。 对于上述选择,团队同学解释道,此前大家也曾考虑研究一个大模型去解决多个任务,但从结果看,实际效果只能达到 70 - 80 分水平,但在时间成本、算力成本方面消耗量较大。 从落地角度出发,团队认为,利用 Scaling Laws 解决一些基础问题更具实际价值。 关于为什么选择深度估计任务,成员介绍道,如果将计算机视觉领域的任务进行分类,文本描述、图像分类等任务均需要有人参与,才有意义。与之相对,边缘检测、光流法运动检测等任务中,相关信号本身就客观存在,结果评价也不需要人类参与。深度估计(Depth Estimation)便可归为此类,相比其他任务,该任务更为“基础”,关联落地场景也较多。 作为计算机视觉领域中的重要任务之一,深度估计旨在从图像中推断出场景内物体的距离信息,应用包括自动驾驶、3D 建模、增强现实等。 此外,深度估计模型还可以作为中间件,整合进视频平台或剪辑软件中,以支持特效制作、视频编辑等功能。目前,已有下游 B 端用户将 Depth Anything V2 内置进产品当中。
下游用户 Quick Depth 将 Depth Anything V2 内置进产品的效果 二、Depth Anything V1 训练过程 Depth Anything 从立项到 V2 版本发布并被苹果选入 Core ML,历经一年左右时间。据成员分享,这当中,最困难部分在于两方面:
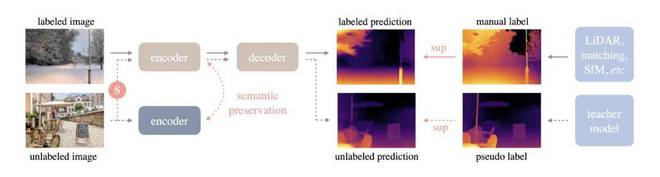
上述两个问题分别导出了 Depth Anything 的 V1 和 V2 版本,我们不妨先从训练模型说起。 事实上,Depth Anything 出现前,MiDaS 已能较好解决深度估计问题。 MiDaS 是一种稳健的单目深度估计模型,相关论文于 2019 年首次提交 ArXiv ,很快中选计算机视觉和人工智能领域顶级国际期刊 TPAMI 。但该模型只开源了模型本身,却未开源训练方法。 为实现训练过程,团队主要做了如下努力。 1. 专门设计了一个数据引擎,收集并自动标注大量数据 该方面努力大大扩展了数据覆盖范围,减小泛化误差。数据增强工具的引入使得模型可主动寻求额外视觉知识,并获得稳健的表示能力。 值得一提的是,起初模型的自训练 Pipeline 并未获得较大提升。团队推测,可能是所用标注数据集内已有相当数量的图像,模型没能从未标注数据获得大量知识。 于是,他们转而以一个更困难的优化目标挑战学生模型:在训练过程中,对无标注图像加入强扰动(颜色失真和空间失真),迫使学生模型主动寻求额外视觉知识。 2. 通过预训练编码器,促使模型继承丰富的语义先验知识 理论上,高维语义信息对于深度估计模型有益,来自其他任务中的辅助监督信号对于伪深度标签有对抗作用。于是,团队便在一开始尝试通过 RAM+GroundingDINO+HQ-SAM 模型组合为无标注图像分配语义标签,但效果有限。团队推测,该现象源于图像解码为离散类空间过程中,损失了大量语义信息。 经过一段时间尝试,团队转而引入了基于预训练编码器的知识蒸馏,促使模型从中继承丰富的语义先验知识,进一步弥补数据标注量比较少的问题。 训练 Pipeline 如下图,实线为有标注图像流,虚线为无标注的图像流,S 表示加入的强扰动。同时,为了让模型拥有丰富的先验语义知识,团队在冻结编码器(Encoder)与在线学生模型之间强制执行了辅助约束,以保留语义能力。 Depth Anything Pipeline 展示
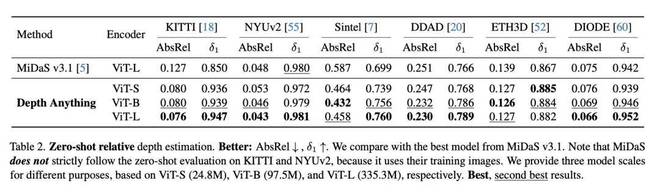
最终,Depth Anything 不仅跟之前成果同等效果,在一些指标上,还超越了参考模型。在下图零样本相对深度估计表现中,Depth Anything 对比 MiDaS v3.1 面向 KITTI 等主流数据集,均有不错表现。其中 AbsRel 数值越低效果越好,δ1 数值越高效果越好。
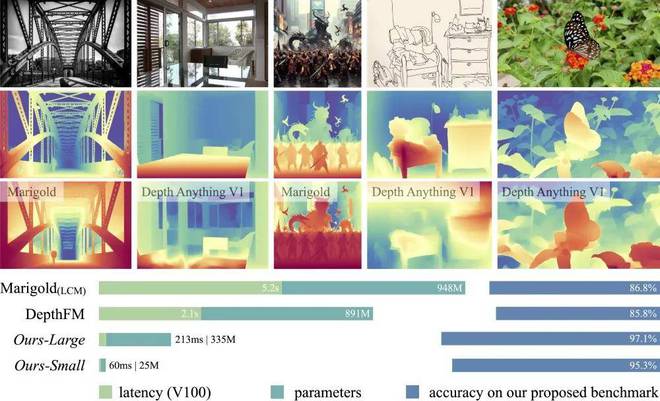
此外,该模型面向 6 个公共数据集和随机拍摄的照片,在零样本能力评估方面也表现出了很强的泛化能力。 三、优化细节与模型规模 Scaling-up 完成 V1 版本训练后,团队对模型进行进一步优化并提升鲁棒性,还比照了其它类型模型的效果。 具体来说,基于稳定扩散的 Marigold 属于生成式单目深度估计模型,对于细节问题,以及透明物体、反射表面单目深度估计问题能很好解决,但复杂度、效率、通用性方面有所不足。Depth Anything V1 的特征则与其互补。
为解决上述问题,团队尝试了各种方法及探索,包括调整预训练模型、修改 Loss 、数据增强等等。 这一过程中,有三点重要发现: 其一,精确的合成数据能在细节方面带来更好表现。 通过对比其他模型(比如:Marigold ),团队发现,对于细节问题,稳定扩散模型并非唯一解。判别式的单目深度估计模型在细节问题方面,依然可以有很好表现能力。关键在于用精确的合成图像数据替换带标注的真实图像数据。 团队认为,真实带标注的数据存在两个缺点。其一是标注信息不可避免包含不准确的估计结果,这可能源自传感器无法捕捉,也可能来自算法影响。其二,真实数据集忽略了一些深度细节,比如对于树木、椅子腿等表示较为粗糙,造成了模型表现不佳。
其二,此前很多成果未使用合成数据,源于合成数据本身在之前存在较大缺陷。 以 DINOv2-G 为例,模型基于纯合成数据训练会产生很大误差,其原因在于,合成图像与真实图像本身存在差异,比如颜色过于“干净”,布局过于“有序”,而真实图像则有更强随机性。此外,合成图像的场景有限,势必影响模型通用性。 团队针对 BEiT、SAM、DINOv2 等模型泛化性的对比,结果发现只有 DINOv2-G 达到了满意效果,其他均存在严重泛化问题。
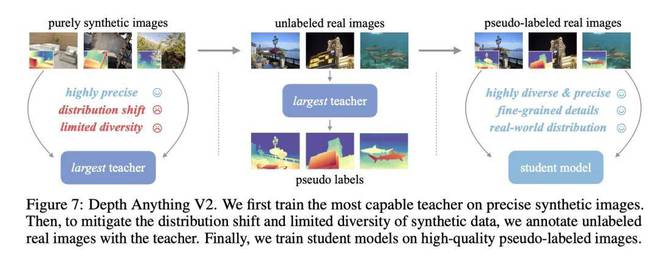
其三,针对合成图像数据扬长避短的方法:用合成数据训练教师模型并扩大模型规模,接着,以大规模的伪标注真实图像为桥梁,教授较小的学生模型。 基于上述思路,团队构建了训练 Depth Anything V2 的 Pipeline ,具体来说,先基于高质量的合成图像,训练基于 DINOv2-G 的教师模型,再在大量未标记的真实图像上产生精确的伪标注深度信息,最后,基于伪标注的真实图像训练学生模型,以获取高鲁棒的泛化能力。
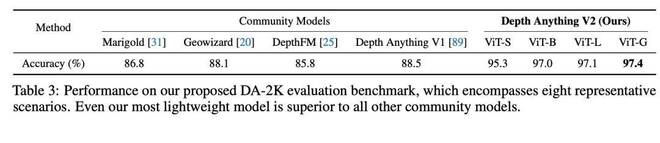
为了更好评价模型表现,团队还提出了 DA-2K 评价基准。它考虑了精确的深度关系、覆盖了广泛场景,并包含大量高分辨率图像及 8 个代表性场景。基于该基准, Depth Anything V2 ViT-G 版本明显优于 Marigold 及 Depth Anything V1 在内的之前成果。
除了针对数据的相关研究,团队还尝试扩大了教师模型容量,以探索模型规模 Scaling 对效果的影响。 通过研究,团队发现,规模较小的教师模型泛化能力的确不如较大规模模型,此外,不同类型的预训练编码器提升规模后,带来的泛化提升差异很大,比如 BEiT 、SAM 等主流预训练编码器表现明显不如 DinoV2 。 上述种种努力持续数月,最终,Depth Anything 模型在鲁棒性和细节丰富度上都有较大提升,且相比基于稳定扩散技术构建的最新模型速度快 10 倍以上,效率更高。
与之相对,预训练的扩散模型在细节方面表现更佳。团队同学表示,此前也曾考虑使用更复杂的模型,但通过深入研究,考虑落地成本、实际需求等因素,Feed-forward 结构目前仍是更适合落地的选择。 回望整个过程,参与同学感慨:“研究工作其实没特别多所谓的灵感迸发瞬间,更多的,还是踏踏实实逐个把设想方法尝试一遍,才能取得成绩”。 最后,展望 Scaling Laws 对 CV 发展的影响,团队认为,Scaling Laws 在未来将更有助于解决此前一直存在,且难以突破的基础任务,充分发挥数据、模型 Scaling 的价值。至于 Scaling 不断提升的边界在哪?团队还在进一步探索中。 四、论文一作为实习生 目前,Depth Anything 已有2个版本模型系列发布,相关论文 Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data 已中选 CVPR 2024。
该系列成果一作为团队实习生,相关研究工作也是在公司实习期间完成。 立项时,由 Mentor 提出了规模 Scaling 的路线,并给到最初项目设想,实习生进一步提出用大规模未标注数据去 Scaling-up 的想法。不到一年,该同学就完成了相关成果的上手实验、项目推进、论文撰写等大部分工作。 期间,公司科学家与团队 Mentor 相应提供了建议与指导,持续跟踪进展,并出面跟合作部门协调计算资源。 “我们在研究工作上,会更多聚焦在给出好问题,并在一些关键节点把控项目推进方向,提供给实习生适当的方案思路,执行上,充分信任同学们”,项目 Mentor 分享道。 这样既能尊重实习同学想法,也能避免完全不管,没有产出,他认为。 在大家的共同努力下,该实习同学不仅收获了成果,能力也获得较大提升,个人研究品位及独立发现解决问题能力颇受团队认可。 关于个人成长与团队支持,实习同学认为,公司和组里提供了自由研究氛围,对于合理思路都比较支持。 “而且相比 Paper 数量,团队会鼓励花更多时间研究更难、更本质、更能为行业提供新视角和新价值的问题”,他补充道。 事实上,Depth Anything 只是众多成果之一,字节跳动近期在视觉生成及大模型相关领域的研究探索还有很多。
目前,字节跳动大模型计算机视觉方向正在持续招揽优秀人才,如果你也渴望在自由的研究氛围里,参与计算机视觉技术的的前沿探索,欢迎投递简历。 投递链接:https://jobs.bytedance.com/campus/position?keywords=%E8%B1%86%E5%8C%85%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%9B%A2%E9%98%9F%20%E8%A7%86%E8%A7%89&category=&location=&project=&type=&job_hot_flag=¤t=1&limit=10&functionCategory=&tag=&spread=XKDERUX 来源网址:https://www.163.com/dy/article/J6R1E1HI0511AQHO.html |