作者:CSDN博客
什么是LangGraph?
1. LangGraph 与 传统 LangChain
技术定义: LangChain 主要用于构建线性的工作流(DAG,有向无环图),数据从头传到尾。而 LangGraph 是 LangChain 的扩展框架,专门用于构建包含“循环(Cycles)”和“状态记忆(Stateful)”的多智能体(Multi-Agent)应用。
简单举例: 传统的 LangChain 像是一条单向流水线,原材料进去,经过几道工序,成品出来,不能回头。LangGraph 像是一个带环岛的交通网络或者一个带有反馈机制的办公室。员工(大模型)在遇到无法解答的问题时,可以去查资料(调用工具),查完资料后带着结果重新循环回到大脑中进行二次思考,直到问题真正解决才输出最终答案。
- # 传统 LangChain (单向 Pipeline,无法循环)
- chain = prompt | llm | output_parser
- # LangGraph (基于状态图,支持复杂循环)
- builder = StateGraph(AgentState)
- # ... 添加节点与边 ...
- graph = builder.compile()
技术定义: 图中所有节点共享的数据结构(通常是 Python 的 TypedDict 或 Pydantic 模型)。每次节点执行完毕后,都会返回一个更新,LangGraph 会将这个更新合并到全局状态中,传递给下一个节点。
简单举例: State 就像是会议室桌子上的一块公共白板。所有的参会者(节点)都能看到白板上的历史讨论记录(上下文对话),当轮到某个人发言或工作时,他会把自己的新发现写在白板上,供下一个人参考。
- from typing import TypedDict
- # 定义这块“公共白板”上能写哪些字段
- class AgentState(TypedDict):
- input_query: str # 用户的初始问题
- search_results: list[str] # 存放查找到的资料
- final_answer: str # 最终输出的答案
技术定义: 图中的处理单元,本质上就是接收 State、执行特定逻辑(如调用 LLM 或执行 Python 代码),然后返回 State 更新的普通 Python 函数。
简单举例: 节点就是公司里的具体岗位员工。比如“研究员节点”负责去搜索引擎找资料,“总结员节点”负责把资料写成报告。他们只负责自己份内的工作。
- # 一个典型的节点函数(员工)
- def researcher_node(state: AgentState):
- query = state["input_query"]
- # 模拟执行外部搜索
- results = [f"关于 {query} 的搜索结果A", "结果B"]
-
- # 只需要返回需要更新到白板上的增量数据
- return {"search_results": results}
技术定义: 边定义了节点之间的执行顺序。条件边(Conditional Edge)则是一个路由函数,它根据当前的 State 动态决定下一步该走向哪个节点。
简单举例: 边就像是公司的汇报流程图。而“条件边”则是项目经理,他会根据当前白板(State)上的情况做判断:“如果资料查全了,就发给总结员(走向结束);如果资料不够,就打回去让研究员继续查(形成循环)。”
- # 路由函数(项目经理)
- def route_logic(state: AgentState):
- if len(state.get("search_results", [])) > 0:
- return "summarizer" # 资料够了,去写总结
- return "researcher" # 资料不够,打回去继续查
- # 普通边:researcher 节点做完后,强制走到 router_node
- builder.add_edge("researcher", "router_node")
- # 条件边:根据 route_logic 的返回值动态决定去向
- builder.add_conditional_edges("router_node", route_logic)
技术定义: 定义在 State 字段上的数据合并逻辑。默认情况下,节点返回的数据会覆盖全局 State 中的同名字段;如果配置了 Reducer,LangGraph 会调用该函数,将新数据合并或追加到旧数据上。
简单举例: 如果没有 Reducer,会议白板上的字会被下一个人直接擦掉重写;配置了 Reducer,相当于在白板上划分了专门的“留言区”,新来的内容会排在旧留言下面,保留完整历史。
- import operator
- from typing import Annotated, TypedDict
- class AgentState(TypedDict):
- # 没有 Reducer:状态被直接覆盖 (擦掉重写)
- current_status: str
-
- # 有 Reducer (operator.add):新列表会追加到老列表后面 (保留历史)
- messages: Annotated[list[str], operator.add]
技术定义: LangGraph 的状态持久层组件。它会在图的每一步执行完毕后,将完整的 State 拍一个快照(Snapshot)保存下来。这是实现时光倒流 (Time Travel) 和人类介入 (Human-in-the-loop) 的基石。
简单举例: 就像单机游戏的“自动存档”功能。如果打 Boss(调用工具)时报错了,你可以直接读档回到打 Boss 前的状态重试。
- from langgraph.checkpoint.memory import MemorySaver
- # 1. 初始化保存器 (也支持 SQLite/Postgres 等数据库)
- memory = MemorySaver()
- # 2. 编译时注入保存器
- app = builder.compile(checkpointer=memory)
- # 3. 运行时必须指定线程 ID,用于隔离不同用户的“游戏存档”
- config = {"configurable": {"thread_id": "user_123_session_1"}}
- app.invoke({"input_query": "你好"}, config=config)
技术定义: 将一个已经编译好的 StateGraph 实例作为一个普通的 Node,无缝嵌入到另一个更大的图(父图)中。专门用于降低复杂 Agent 系统的代码耦合度。
简单举例: 就像大公司里的“部门外包”。父图是总公司,遇到复杂的财务问题时,直接把任务扔给“财务部(子图)”。财务部内部有自己的一套流转节点,搞定后直接把最终结果交回给总公司。
- # 1. 编译子图 (财务部门)
- finance_graph = StateGraph(FinanceState)
- # ... 给财务部添加主管、会计节点 ...
- finance_app = finance_graph.compile()
- # 2. 将子图作为普通节点,无缝接入父图 (总公司)
- main_graph = StateGraph(MainState)
- main_graph.add_node("finance_department", finance_app)
技术定义: LangGraph 提供的用于实现动态并行执行的核心 API。在条件边中返回 Send 对象,LangGraph 会同时拉起多个相同的节点并发处理不同数据,最后汇总结果。
简单举例: 就像老师批改 50 份期末试卷。老师不自己挨个批改(串行),而是把试卷同时分发给 5 个助教(并行 Send 拉起 5 个节点),改完后再将分数统一汇总给老师。
- from langgraph.constants import Send
- def distribute_grading(state: GlobalState):
- papers = state["exam_papers"]
- # 动态返回多个 Send 对象,并行拉起多个 grader_node
- return [Send("grader_node", {"paper_content": p}) for p in papers]
- # 起点直接触发分发逻辑
- builder.add_conditional_edges("start", distribute_grading)
技术定义: 一种在 Node 内部直接返回的特殊数据类。它允许节点在更新 State 的同时,动态指定下一步要跳转的目标节点,将“状态更新”和“路由跳转”合二为一。
简单举例: 以前员工干完活(节点),要把结果写在白板上等经理(条件边)决定下一步。现在员工自带分配权(Command),干完活不仅更新白板,还能直接指定“转交给谁干”。
- from langgraph.types import Command
- def smart_worker_node(state: AgentState):
- # 干完活了
- result = "数据分析报告已生成"
-
- # 以前只能 return {"final_answer": result},然后靠外部判断
- # 现在直接用 Command 决定去向:更新状态并强制跳到 manager_node
- return Command(
- update={"final_answer": result},
- goto="manager_node"
- )
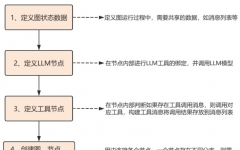
第一步:环境安装与导入
安装 LangGraph 和基础依赖环境。- # 安装基础包
- # pip install -U langgraph langchain-openai
- from typing import TypedDict, Annotated
- from langgraph.graph import StateGraph, START, END
- from langgraph.graph.message import add_messages
我们需要定义图在流转过程中传递的数据结构,最典型的用法是保存对话历史记录。- # 定义状态字典,Annotated[list, add_messages] 引入了 Reducer 聚合器
- # 告诉框架:新消息要追加到列表中,而不是覆盖
- class AgentState(TypedDict):
- messages: Annotated[list, add_messages]
创建具体的处理函数。这里模拟两个节点:思考的大模型和外部工具。- # 1. 模拟大模型节点:根据当前消息思考
- def call_llm(state: AgentState):
- messages = state['messages']
- last_message = messages[-1]
-
- if "天气" in last_message:
- return {"messages": ["CALL_TOOL: weather_api"]}
- else:
- return {"messages": ["我是一个AI,我已经为你解答了问题。"]}
- # 2. 模拟工具节点:执行具体的外部查询
- def execute_tool(state: AgentState):
- return {"messages": ["工具执行结果:今天天气晴朗,气温25度。"]}
写一个逻辑函数,决定大模型思考完之后,是直接结束,还是去调用工具。- # 路由逻辑:判断下一步去哪里
- def should_continue(state: AgentState):
- last_message = state['messages'][-1]
-
- if "CALL_TOOL" in last_message:
- return "continue_to_tool"
- return "end_conversation"
将状态、节点和边像拼图一样组装起来。- workflow = StateGraph(AgentState)
- workflow.add_node("agent", call_llm)
- workflow.add_node("tool", execute_tool)
- workflow.add_edge(START, "agent")
- workflow.add_conditional_edges(
- "agent",
- should_continue,
- {
- "continue_to_tool": "tool",
- "end_conversation": END
- }
- )
- workflow.add_edge("tool", "agent")
- app = workflow.compile()
向图中输入初始状态,观察数据的流转。- # 测试 1:不需要工具的普通对话 (START -> agent -> END)
- inputs = {"messages": ["你好,请介绍一下你自己。"]}
- for output in app.stream(inputs):
- print("当前节点输出:", output)
- print("---")
- # 测试 2:触发工具调用的复杂对话 (START -> agent -> tool -> agent -> END)
- inputs = {"messages": ["北京今天的天气怎么样?"]}
- for output in app.stream(inputs):
- print("当前节点输出:", output)
在需要并行查询多个数据源时使用。- from langgraph.constants import Send
- import operator
- # 状态定义:使用 operator.add 作为 Reducer 来累加多个并行节点的结果
- class ParallelState(TypedDict):
- topics: list[str]
- reports: Annotated[list[str], operator.add]
- def generate_report(state: str):
- return {"reports": [f"【{state}】的调研报告已生成"]}
- def continue_to_parallel(state: ParallelState):
- # 返回多个 Send 对象,LangGraph 会并行触发 generate_report 节点
- return [Send("generate_report", topic) for topic in state["topics"]]
- parallel_workflow = StateGraph(ParallelState)
- parallel_workflow.add_node("generate_report", generate_report)
- parallel_workflow.add_conditional_edges(START, continue_to_parallel)
- parallel_workflow.add_edge("generate_report", END)
- app_parallel = parallel_workflow.compile()
抛弃繁琐的 add_conditional_edges,让节点自己决定去向。- from langgraph.types import Command
- def smart_agent_node(state: AgentState):
- messages = state['messages']
- last_message = messages[-1]
-
- if "查天气" in last_message:
- # Command 方式:同时更新状态并指定去向
- return Command(
- goto="tool",
- update={"messages": ["准备调用天气工具..."]}
- )
- else:
- return Command(
- goto=END,
- update={"messages": ["直接回答问题,结束流程。"]}
- )
- command_workflow = StateGraph(AgentState)
- command_workflow.add_node("agent", smart_agent_node)
- command_workflow.add_node("tool", execute_tool)
- command_workflow.add_edge(START, "agent")
- # 节点自带 goto 逻辑,无需再写 add_conditional_edges
当你掌握了基础的图结构后,LangGraph 在生产环境中的两大杀手锏是记忆持久化(Persistence)和人工干预(Human-in-the-loop)。
在编译图时,你可以传入一个 checkpointer(如基于 SQLite 或 Postgres 的保存器)。加入保存器后,图不仅能在单个循环中流转状态,还能将状态永久保存在数据库中。这意味着你可以实现线程级别的断点续传:
你的 Agent 可以在执行完某个高风险操作(如发送邮件前)自动暂停。
状态被冻结,等待人类用户确认(或直接在 UI 界面中修改 State 里的 API 请求参数)。
人类审批通过后,Agent 读取之前的状态,继续往下执行。
- # 进阶编译示例(引入持久化检查点)
- # from langgraph.checkpoint.sqlite import SqliteSaver
- # memory = SqliteSaver.from_conn_string(":memory:")
- # app = workflow.compile(checkpointer=memory, interrupt_before=["tool"])
|
























 广告
广告