作者:CSDN博客
目录
一,LangGraph介绍
1.1 认识智能服务(Agent Server)
1.2 LangGraph -- Agent Server 的“操作系统”
1.3 LangGraph生态系统
二,LangGraph核心概念
2.1 Agent
2.2 工作流
2.3 实现工作流的核心概念
State(状态) - 快递的"包裹信息"
Nodes(节点) - 快递站点
Edges(边) - 快递运输路线
三,LangGraph简单示例
3.1 LangGraph编码思路
3.2 智能快递配送系统
1.定义 State,设置快递的"包裹信息"
2.定义 StateGraph 图,成⽴快递公司
3.定义 Nodes,创建配送站点
4.添加 Nodes,建设配送站点
5.添加 Edges,规划运输路线
6.StateGraph 图编译,从公司创建到运⾏
7.完整代码+测试用例
3.3 支持搜索的智能代理系统
1.设置 Nodes
2.设置 State
3.设置 Edges
4.完整代码
3.4基于LangGraph实现的RAG
1.装备知识库并创建检索工具
2.创建节点
3.组装"工作流水线"
4.完整代码
一,LangGraph介绍
LangGraph 是 LangChain 生态中用于构建有状态、图驱动、支持循环 / 分支 / 多智能体协作的 LLM工作流编排框架,核心是用「状态 + 节点 + 边」建模复杂 AI 流程,解决传统线性链难以处理的循环、多轮决策、多角色协作问题。
在 LangChain 中,我们接入 LLM 构建的 AI 系统有以下特点:
单次对话,“记不住”太多上下文
主要是问答模式
相对简单的任务
以前用 LangChain 只能写:
线性流程:A→B→C→结束
没法轻松写:循环、多轮决策、多智能体、分支判断、长上下文记忆
LangGraph 就是为了解决这些:
自主思考的 Agent
多轮工具调用(搜索→计算→查资料→再搜索)
多角色协作(研究员 + 分析师 + 写作)
带循环、分支、重试的复杂工作流
1.1 认识智能服务(Agent Server)
什么是 Agent Server?它是更聪明的 AI 助⼿
想象一个虚拟的“小助手”,它不仅能回答问题,还能:
记住和你聊过的所有事情
执行一连串任务(比如:查天气 → 推荐穿搭 → 提醒带伞)
中途可以等你给出反馈
运行很长时间不会“忘记“
构建 Agent Server 时遇到的四⼤难题:
难题
| 描述
| 状态丢失
| AI处理长任务时容易"忘记"前面步骤
| 难以调试
| 不知道AI为什么做出某个决定
| 无法干预
| 不能中途给AI指导
| 部署困难
| 复杂Agent Server难以上线运行
|
1.2 LangGraph -- Agent Server 的“操作系统”
LangGraph 就像是一个强大且灵活的“Agent Server 操作系统内核”。
它不关心我们具体用什么模型或提示词,而是为我们解决构建复杂、可靠、可交互的 Agent Server 时所面临的状态管理、流程编排、持久化和人工监督等底层⼯程难题。如果我们需要构建超越简单问答的、具备复杂逻辑和长期记忆的AI 应用,LangGraph 就是为此设计的⼯具。
如果把 Agent Server 比作一个公司,那么:
AI 模型 = 员工(干活的人)
工具= 办公设备(电脑、电话)
LangGraph = 项⽬经理 + 流程系统
简单来说,LangGraph 是一个专门用于构建和管理 Agent Server 的底层框架。
1.3 LangGraph生态系统
LangGraph 是 LangChain 产品家族的一部分。可以与 LangSmith(用于追踪、评估、监控)、LangGraph 部署平台(⽤于轻松部署和扩展Agent Server)以及 LangChain(提供大量集成和组件)结合使⽤,形成完整的开发、调试、部署⼯作流。
LangGraph 与 LangChain 顺利集成,但也可以在没有 LangChain 的情况下使用。
二,LangGraph核心概念
2.1 Agent
Agent (智能体) 是⼀个能够感知环境输入、⾃主决策、规划⾏动路径, 并可调⽤⼯具或执⾏操作以达成目标的自主性软件实体。
其核心在于:由大语言模型 (LLM) 动态控制流程走向
想象你有一个超级聪明的程序员助手,你只需要说一句:"把这个项目的单元测试覆盖率提升到 80%."
然后他就自己去看代码、写测试、运⾏构建、检查结果……直到达标为为止⸺中间不需要你插手.
这个"能独立完成任务"的程序, 就是我们说的 Agent (智能体) .
想象一个私人助理机器人:
你说:"帮我安排下周去上海的差旅. "
它不会傻傻地只回复"好的", 而是会:
a. 查天气→ 决定带什么衣服
b. 查航班/高铁时间 → 比较价格
c. 预订酒店 → 发送日程到你的手机
d. 提醒你带身份证
整个过程没有固定的流程图, 它自己"想"出来的步骤 ⸺ 这就是典型的 Agent 行为
2.2 工作流
Workflow (⼯作流) 是⼀个将复杂过程分解为定义明确、顺序执⾏的任务流程, 并在其中⾃动化传递数据与任务的状态, 用户完成特定⽬标. 如果说 Agent 是聪明的执⾏者,那 ⼯作流就是它的⾏动蓝图 ⸺它定义了“先做什么、后做什么、在什么条件下跳转或终止”。
其核心在于:预设的、可重复的流程路径.
比如公司的报销流程
提交发票 → 领导审批 → 财务审核 → 财务结算 → 归档完成
或者一个自动化客服工单系统
用户提交问题 → 系统⾃动分类 → 分配给对应客服 → 客服处理 → 用户评价 → 工单关闭
这个固定路径, 整个过程沿着预设的流程运⾏, 就是典型的⼯作流⾏为.
LangGraph 是实现的就是⼯作流!
在 LangGraph中,工作流基于 LLM ,以及添加到其中的各种增强功能(如工具调用、结构化输出和短期记忆)而实现:
LangGraph 是一个强大且灵活的“Agent Server 操作系统内核”。它不关心我们具体用什么模型或提示词,⽽是为我们解决构建复杂、可靠、可交互的 Agent Server 时所面临的状态管理、流程编排、持久化和人工监督等底层⼯程难题。
2.3 实现工作流的核心概念
如何实现工作流逻辑?图计算是一种⽤节点和边来表示复杂系统的方法。在 AI 领域,它特别适合构建多步骤、有状态的智能工作流。
想象一个快递配送系统,下图展示了包裹从输入(揽收站)到输出(配送站)的过程:
配送站、揽收站、分拣中⼼ = 节点(Node)
运输路线 = 边(Edge)
包裹信息 = 状态(State)
完整配送网 = 图(Graph)
State(状态) - 快递的"包裹信息"
State 就像快递包裹上的标签,记录着包裹的当前位置、目的地、配送状态等信息。在整个配送过程中,所有站点都能查看和更新这个信息。
状态特性:
共享性:所有节点(快递站点)都能读取和修改
持久性:在整个工作流(快递运输)执行期间持续存在
结构化:有明确的字段定义
代码示例:- from typing import TypedDict
- class PackageState(TypedDict):
- # 包裹的状态
- package_id:str #包裹ID
- origin:str #包裹的始发地
- destination:str #包裹的目的地
- #配送状态("揽收中","配送中",...)
- status:str
- # 包裹的流转历史
- # history:list[str] #覆盖更新
- history:Annotated[list[str],operator.add] #追加更新
- # 总里程
- total_instance: Annotated[int,operator.add]
- # 配送详情("加急","普通")
- priority:str
Nodes(节点) - 快递站点
节点就像快递配送⽹络中的各个站点,每个站点负责特定的处理步骤。例如:
揽收站:接收包裹,初始化信息
分拣中心:根据目的地分类包裹
派送站:最终配送至收件人
节点特征:
单一职责:每个节点只做一件事
输入输出:接收状态,返回状态更新
独⽴性:节点间不直接通信,通过 State 交互
代码示例(节点只不过是函数):- import operator
- from typing import TypedDict, Annotated
- # 揽收站节点
- def receive_package(state:PackageState):
- """揽收站"""
- #获取出发地
- origin = state["origin"]
- return {
- "status": "已揽收",
- "history": [f"在{origin}揽收"]
- }
- # 分拣中心节点:根据目的地进行分拣
- def sort_package(state:PackageState):
- """分拣中心站"""
- #获取目的地
- destination = state["destination"]
- if "北京" in destination:
- next = "北京分拣中心"
- elif "西安" in destination:
- next = "西安分拣中心"
- else:
- next = "其他分拣中心"
- return {
- "status" : "已分拣",
- "history": [f"在{next}分拣"]
- }
- # 派送站节点
- def final_delivery(state:PackageState):
- """派送站"""
- destination = state["destination"]
- return {
- "status":"已签收",
- "history":[f"在{destination}签收"]
- }
- # 普通配送站节点
- def standard_delivery(state:PackageState):
- """普通配送"""
- return {
- "status":"运输中",
- "history":["标准陆运"],
- "total_instance":500
- }
- # 加急配送站节点
- def express_delivery(state:PackageState):
- """加急配送"""
- return {
- "status":"加急运输",
- "history":["加急空运"],
- "total_instance":800
- }
边定义了包裹在站点之间的流动路径,就像快递公司的运输路线图。对于路线,一般类型有:
开始/结束路线:流程的开始和结束点(包裹的开始站,与结束站)。
固定路线:包裹可以从揽收站→分拣中⼼(所有包裹都走这条路),而不能从配送站→揽收站,而是配送站→家。
条件路线:根据⽬的地选择不同的分拣中心
实际上在 LangGraph 中,边就定义了节点之间的连接关系,决定了⼯作流的执⾏顺序。边的类型有:
固定边:总是从 A 到 B
条件边:根据状态决定下一步
以及图的开始和结束点,标志了工作流的入口和出口。
因此,LangGraph 通过节点(每个处理步骤)、边(步骤之间的连接)和状态(保存执行过程),就可以构建出一个任务工作流(图)。
三,LangGraph简单示例
3.1 LangGraph编码思路
构建 Graph 图,首先需要【定义状态】,然后【定义并添加节点和边】,最后【编译】它。编译提供了对图形结构的一些基本检查(没有孤立节点等)。
LangGraph 所谓的“编译” 与 传统意义上的语言编译完全不同,LangGraph 编译本质是在运行时动态构建和验证一个复杂的图,而非翻译代码。
3.2 智能快递配送系统
1.定义 State,设置快递的"包裹信息"
定义图时要做的第一件事是定义图的 状态 。 状态 将是图中所有 节点 和 边 的输入,可以是TypedDict 或 Pydantic 模型( Pydantic 的性能不如 TypedDict )。
如下所示:- class PackageState(TypedDict):
- # 包裹的状态
- package_id:str #包裹ID
- origin:str #包裹的始发地
- destination:str #包裹的目的地
- #配送状态("揽收中","配送中",...)
- status:str
- # 包裹的流转历史
- # history:list[str] #覆盖更新
- history:Annotated[list[str],operator.add] #追加更新
- # 总里程
- total_instance: Annotated[int,operator.add]
- # 配送详情("加急","普通")
- priority:str
如下所示:- # 覆盖更新:每次新状态替换旧状态
- status: str
- # 追加更新:新的流转记录添加到历史列表
- history: Annotated[list[str], add]
- # 数值累加:⾥程数累加
- total_distance: Annotated[int, add]
StateGraph 是一个有状态图计算框架,它基于有向图(Directed Graph) 模型构建,专门设计用于处理多步骤、有状态的工作流程。
StateGraph 用来将复杂的工作流程可视化、模块化,让开发者能够像设计快递配送网路一样设计软件系统。通过这种思维方式,即使是复杂的多步骤 AI 应⽤也变得清晰可控。
我们需要使用 langgraph.graph.state.StateGraph 来定义。 StateGraph 仅是⼀个构建器类,可以使⽤State来构建。
如下所示:- from langgraph.graph import StateGraph
- # 2. 成⽴快递公司
- delivery = StateGraph(PackageState)
接着我们可以定义各个配送站点(节点)。在 LangGraph 中, 节点就是一个Python 函数(同步或异步)。注意
节点 接收 状态 作为参数。
节点 不需要返回整个 状态 模式,只需一个更新。
如下所示:- # 揽收站节点
- def receive_package(state:PackageState):
- """揽收站"""
- #获取出发地
- origin = state["origin"]
- return {
- "status": "已揽收",
- "history": [f"在{origin}揽收"]
- }
- # 分拣中心节点:根据目的地进行分拣
- def sort_package(state:PackageState):
- """分拣中心站"""
- #获取目的地
- destination = state["destination"]
- if "北京" in destination:
- next = "北京分拣中心"
- elif "西安" in destination:
- next = "西安分拣中心"
- else:
- next = "其他分拣中心"
- return {
- "status" : "已分拣",
- "history": [f"在{next}分拣"]
- }
- # 派送站节点
- def final_delivery(state:PackageState):
- """派送站"""
- destination = state["destination"]
- return {
- "status":"已签收",
- "history":[f"在{destination}签收"]
- }
- # 普通配送站节点
- def standard_delivery(state:PackageState):
- """普通配送"""
- return {
- "status":"运输中",
- "history":["标准陆运"],
- "total_instance":500
- }
- # 加急配送站节点
- def express_delivery(state:PackageState):
- """加急配送"""
- return {
- "status":"加急运输",
- "history":["加急空运"],
- "total_instance":800
- }
接下来,我们需要将各节点,组织进图中,即添加节点到 StateGraph 中。可以使用add_node() 将新节点添加到 StateGraph 。- # 3.定义图
- delivery = StateGraph(PackageState)
- # 4.添加节点
- delivery.add_node("揽收站",receive_package)
- delivery.add_node("分拣中心",sort_package)
- delivery.add_node("派送站",final_delivery)
- delivery.add_node("普通派送站",standard_delivery)
- delivery.add_node("加急派送站",express_delivery)
各节点(站点)准备好后,则需要为快递运输规划。
实际上,这就是为 图 定义 边 。边有几种关键类型:
普通边/固定边(Normal Edges):直接从一个节点转到下一个节点。
条件边(Conditional Edges):调⽤函数来确定下一步要转到哪个节点。
例如,设置最简单运输路线:快递由揽收站接收,下⼀站固定为分拣中⼼,最后到派送中进⾏派送。- # 固定边
- delivery.add_edge(START,"揽收站")
- delivery.add_edge("揽收站","分拣中心")
- def select_delivery(state:PackageState):
- priority=state["priority"]
- if priority=="加急":
- return "备注加急"
- elif priority=="普通":
- return "无备注"
- # 添加条件边
- delivery.add_conditional_edges(
- "分拣中心", #条件起始节点
- select_delivery, #确定下个节点的可调用对象
- {
- "备注加急":"加急派送站",
- "无备注":"普通派送站"
- }
- )
- # 添加固定边
- delivery.add_edge("加急派送站","派送站")
- delivery.add_edge("普通派送站","派送站")
- delivery.add_edge("派送站",END)
START 节点:是一个特殊节点,表⽰将⽤⼾输入发送到图形的节点。引⽤此节点的主要目的是确定应该⾸先调用哪些节点。
END 节点:是一个表示终端节点的特殊节点。当想要指示哪些边在完成后没有后续动作时,将引用此节点。
条件入口点(Conditional Entry Point):调⽤一个函数来确定在⽤⼾输入到达时⾸先调⽤哪个节点
6.StateGraph 图编译,从公司创建到运⾏
在步骤2中,我们仅是构建出 StateGraph ,还无法直接⽤于执⾏。LangGraph 要求:必须先编译图,然后才能使⽤它。编译提供了对图结构的一些基本检查,这会验证:
从 START 到所有节点的可达性
从所有节点到 END 的可达性
没有孤⽴节点或死循环
使⽤ compile() 方法即可编译图。该⽅法将 StateGraph 编译为 CompiledStateGraph 对象。编译后的图实现了 Runnable 接⼝,可以异步调⽤、流式传输、批处理和运⾏。
代码如下:- # 7. 编译系统
- delivery_system = delivery.compile()
- # 智能快递派送系统
- import operator
- from typing import TypedDict, Annotated
- from langgraph.constants import START, END
- from langgraph.graph import StateGraph
- # 1.状态定义(定义包裹的状态)
- class PackageState(TypedDict):
- # 包裹的状态
- package_id:str #包裹ID
- origin:str #包裹的始发地
- destination:str #包裹的目的地
- #配送状态("揽收中","配送中",...)
- status:str
- # 包裹的流转历史
- # history:list[str] #覆盖更新
- history:Annotated[list[str],operator.add] #追加更新
- # 总里程
- total_instance: Annotated[int,operator.add]
- # 配送详情("加急","普通")
- priority:str
- # 2.节点定义(定义函数)
- # 节点之间使用状态(state)进行通信
- # 揽收站节点
- def receive_package(state:PackageState):
- """揽收站"""
- #获取出发地
- origin = state["origin"]
- return {
- "status": "已揽收",
- "history": [f"在{origin}揽收"]
- }
- # 分拣中心节点:根据目的地进行分拣
- def sort_package(state:PackageState):
- """分拣中心站"""
- #获取目的地
- destination = state["destination"]
- if "北京" in destination:
- next = "北京分拣中心"
- elif "西安" in destination:
- next = "西安分拣中心"
- else:
- next = "其他分拣中心"
- return {
- "status" : "已分拣",
- "history": [f"在{next}分拣"]
- }
- # 派送站节点
- def final_delivery(state:PackageState):
- """派送站"""
- destination = state["destination"]
- return {
- "status":"已签收",
- "history":[f"在{destination}签收"]
- }
- # 普通配送站节点
- def standard_delivery(state:PackageState):
- """普通配送"""
- return {
- "status":"运输中",
- "history":["标准陆运"],
- "total_instance":500
- }
- # 加急配送站节点
- def express_delivery(state:PackageState):
- """加急配送"""
- return {
- "status":"加急运输",
- "history":["加急空运"],
- "total_instance":800
- }
- # 3.定义图
- delivery = StateGraph(PackageState)
- # 4.添加节点
- delivery.add_node("揽收站",receive_package)
- delivery.add_node("分拣中心",sort_package)
- delivery.add_node("派送站",final_delivery)
- delivery.add_node("普通派送站",standard_delivery)
- delivery.add_node("加急派送站",express_delivery)
- # 5.添加边
- # 固定边
- delivery.add_edge(START,"揽收站")
- delivery.add_edge("揽收站","分拣中心")
- def select_delivery(state:PackageState):
- priority=state["priority"]
- if priority=="加急":
- return "备注加急"
- elif priority=="普通":
- return "无备注"
- # 添加条件边
- delivery.add_conditional_edges(
- "分拣中心", #条件起始节点
- select_delivery, #确定下个节点的可调用对象
- {
- "备注加急":"加急派送站",
- "无备注":"普通派送站"
- }
- )
- # 添加固定边
- delivery.add_edge("加急派送站","派送站")
- delivery.add_edge("普通派送站","派送站")
- delivery.add_edge("派送站",END)
- # 6.编译图
- delivery_system = delivery.compile()
- # 7.执行图(输入初始状态,输出最终状态)
- test_packages=[
- {
- "package_id":"p001",
- "origin":"北京",
- "destination":"上海",
- "priority":"加急",
- "history":[],
- "total_instance":0
- },
- {
- "package_id": "p002",
- "origin": "西安",
- "destination": "杭州",
- "priority": "普通",
- "history": [],
- "total_instance": 0
- }
- ]
- for package in test_packages:
- print(f"\n配送包裹:{package['package_id']}")
- #执行图
- result = delivery_system.invoke(package)
- print("最终状态:",result["status"])
- print("配送历史",result["history"])
- print("总里程",result["total_instance"])

到此,我们已经构建出了⼀个图式的智能快递配送系统:
State = 包裹信息卡(记录所有状态)
Nodes = 配送站点(执⾏具体操作)
Edges = 运输路线(控制流转顺序)
Reducers = 信息更新规则(如何记录变更)
编译 = 从路线图到运营系统的转换
3.3 支持搜索的智能代理系统
核心功能如下:
智能对话与工具调用:基于聊天模型,能够理解用户问题并决定是否需要调用搜索⼯具
自动搜索整合:通过 Tavily 搜索工具获取实时信息,并将搜索结果整合到回答中
循环决策机制:能够多次调⽤工具和模型,直到获得满意答案
流程设置如下
1.设置 Nodes
根据节点的单一职责特性,即每个节点只做一件事,我们可以设置:
节点1( tool_node ):专门负责搜索,获取搜索结果。
节点2( llm_call ):专门负责调用LLM,获取最终结果。
根据节点的独立性特性,即每个节点间不直接通信,⽽是通过 State 交互。它们接收 State,返回State 的更新。
2.设置 State
根据状态的共享性特性,即所有节点都能读取和修改状态。LangGraph 在许多情况下,将以前的对话历史记录存储为 State 中的消息列表会很有帮助,这样就能通过 State 中的消息列表来跟踪整个对话的完整历史,这是构建对话系统的关键。
为此,我们可以在图状态中添加一个 messages 键,如下所示:- class MessageState(TypedDict):
- #消息列表(AIMessage,ToolMessage,HumanMessage)
- messages:Annotated[list[AnyMessage],operator.add]
- #LLM调用次数
- llm_calls:Annotated[int,operator.add]
已经定义了两个节点:
节点1( tool_node ):专门负责搜索,获取搜索结果。
节点2( llm_call ):专门负责调用 LLM,获取最终结果。
因此,可以定义以下逻辑:
对于开始逻辑:是当用户进行输入后,直接让 LLM 进行处理。是否需要搜索⼯具调用,也是通过LLM 进行判断。因此图的入口点则是 llm_call 节点。
对于结束逻辑:可以根据 LLM 返回的结构判断是否调用工具,来决定我们是应该继续循环还是停止循环:
如果 LLM 要调用工具,则进入tool_node节点进行处理;
如果 LLM 不要调用工具,则结束。
4.完整代码
- # 支持搜索的智能代理系统
- import operator
- from typing import TypedDict, Annotated
- from langchain.chat_models import init_chat_model
- from langchain_core.messages import AnyMessage, SystemMessage, ToolMessage, HumanMessage
- from langchain_tavily import TavilySearch
- from langgraph.constants import START, END
- from langgraph.graph import StateGraph
- # 定义工具,模型绑定工具
- search=TavilySearch(max_results=4)
- tools =[search]
- model = init_chat_model(model="gpt-4o-mini")
- #绑定工具
- model_with_tools=model.bind_tools(tools)
- # 1.定义状态
- class MessageState(TypedDict):
- #消息列表(AIMessage,ToolMessage,HumanMessage)
- messages:Annotated[list[AnyMessage],operator.add]
- #LLM调用次数
- llm_calls:Annotated[int,operator.add]
- # 2.定义节点
- # 定义调用llm节点
- # 可能是由START节点过来的
- # 也可能是由"工具调用"节点过来的
- def llm_call(state:MessageState):
- """LLM决定是否调用工具"""
- # 如果是由START节点过来的,state中的messages就只包含用户输入的消息(HumanMessage)
- # 如果是由"工具调用"节点过来的,state中的messages就包含(HumanMessage,AIMessage,ToolMessage)
- messages = state["messages"]
- # result可能1: 带有tool_calls的AIMessage
- # result可能2: 不带tool_calls的AIMesssage
- result = model_with_tools.invoke(
- [
- SystemMessage("你是一个乐于助人的助手,支持调用工具进行搜索")
- ]
- + messages
- )
- return {
- "messages": [result],
- "llm_calls":1
- }
- # 获取所有工具的名称
- # 工具名称和工具的映射
- tools_by_name = {tool.name:tool for tool in tools}
- # 定义调用工具节点
- def tool_node(state:MessageState):
- # 此时的AIMessage中一定包含工具调用的信息(tool_calls)
- # 我们需要找到对应的工具并调用
- # 当前state中的messages中的AIMessage就包含工具调用的信息(tool_call)
- # 例如: 工具的ID,工具的参数,工具的名称
- result = [] # 填充ToolMessage(工具的执行结果)
- for tool_call in state["messages"][-1].tool_calls:
- tool = tools_by_name[tool_call["name"]] # 由工具名称找到对应的工具
- obs = tool.invoke(tool_call["args"]) # 传入参数,调用工具
- result.append(ToolMessage(content=obs,tool_call_id=tool_call["id"]))
- return {
- "messages":result
- }
- # 3.定义图,添加节点和边
- agent_builder = StateGraph(MessageState)
- agent_builder.add_node(llm_call)
- agent_builder.add_node(tool_node)
- # 设置固定边
- agent_builder.add_edge(START,"llm_call")
- def should_continue(state:MessageState):
- # 如果state中的messages的AIMessage中包含tool_call,则要走tool_node节点
- last_message = state["messages"][-1]
- if last_message.tool_calls:
- return "tool_node"
- return END
- # 设置条件边
- agent_builder.add_conditional_edges(
- "llm_call",
- should_continue,
- ["tool_node",END]
- )
- agent_builder.add_edge("tool_node","llm_call")
- # 4.编译图
- agent_search = agent_builder.compile()
- # 5.执行图
- result = agent_search.invoke({
- "messages":[HumanMessage(content="今天西安的天气怎么样?")]
- })
- print(f"一共调用llm{result['llm_calls']}次")
- for msg in result["messages"]:
- msg.pretty_print()
构建一个智能文档问答系统,核心思路如下:
模块化设计:每个节点只做一件事,职责清晰
质量闭环:检索 → 检查 → 优化 → 再检索,确保答案质量
智能路由:AI 自主决定下一步⾏动,无需人工干预
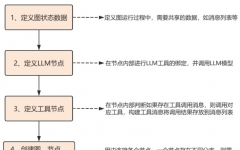
因此,我们需要:
第一步:准备"知识库"(数据加载与处理)
第二步:创建"检索工具"
第三步:设计"工作流程节点"
节点1:决策节点 generate_query_or_respond
节点2:检索器工具节点 retrieve
节点3:问题优化节点 rewrite_question
节点4:答案生成节点 generate_answer
第四步:组装"工作流水线"
条件边1:LLM 决策是否需要进行知识库检索
条件边2:检测【检索到的文档】是否与【问题】相关
最终graph示意图:
1.装备知识库并创建检索工具
- # 1.准备知识库,并创建检索工具
- # 创建聊天模型与嵌入式模型
- model = init_chat_model("gpt-4o-mini")
- embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
- # 文档列表
- paths =[
- "../Docs/MarkDown/城市展厅项目.md",
- "../Docs/MarkDown/智能PPT导览项目.md",
- "../Docs/MarkDown/记忆岛项目.md"
- ]
- # 文档加载器
- # 得到的一个结果的结构类似:
- # [Document(page_content="文档1内容", metadata={"source": "doc1.md"})]
- docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
- # docs = [
- # [Document(page_content="test1的内容", metadata={"source": "test1.md"})],
- # [Document(page_content="test2的内容", metadata={"source": "test2.md"})]
- # ]
- # 把嵌套列表转换成扁平列表
- docs_list = [item for sublist in docs for item in sublist]
- # docs_list = [
- # Document(page_content="test1的内容", metadata={"source": "test1.md"}),
- # Document(page_content="test2的内容", metadata={"source": "test2.md"})
- # ]
- # 使用分词器对文档进行分割
- text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
- encoding_name="cl100k_base",
- chunk_size=1000,
- chunk_overlap=50
- )
- doc_splits = text_splitter.split_documents(docs_list)
- # 使用嵌入模型将文档转化为向量,使用内存数据库存储
- vector_store = InMemoryVectorStore.from_documents(
- documents=doc_splits,
- embedding=embedding_model
- )
- # 使⽤ LangChain 的预构建 create_retriever_tool 创建检索器⼯具
- retriever = vector_store.as_retriever(search_kwargs={"k": 2})
- retriever_tool = create_retriever_tool(
- retriever,
- "retrieve",
- "搜索并返回有关城市展厅/智能PPT导览/记忆岛项目开发的信息。",
- )
generate_query_or_respond节点
该节点核心设计:
决定是直接回答还是检索文档
可以使用 model.bind_tools([retriever_tool]) 让模型能够调用检索工具- # 2.定义状态
- # 此处可以自定义消息状态
- # 也可以直接使用LangGraph包中提供的MessagesState
- # class MessageState(TypedDict):
- # #消息列表(AIMessage,ToolMessage,HumanMessage)
- # messages:Annotated[list[AnyMessage],operator.add]
- # 3.定义节点
- # 定义决策节点(AI决策是否需要检索)
- # 调用LLM绑定检索工具的节点,判断是否需要调用检索工具
- def generate_query_or_respond(state:MessagesState):
- """调用模型基于当前的状态生成响应,给定问题,它将决定是否使用工具进行检索,或者是直接给用户返回答案"""
- result = model.bind_tools([retriever_tool]).invoke(state["messages"])
- # result是AIMessage,可能包含tool_calls,也可能不包含
- return {
- "messages":[result]
- }
前⾯已经创建好了检索器工具。对于节点,可以使用 ToolNode 类来定义:- # 定义工具节点,调用检索工具
- # 可以实现一个函数,函数中调用工具
- # 也可以直接使用LangGraph提供的ToolNode来生成工具节点
- retriever_node = ToolNode([retriever_tool])
该节点主要负责当文档不相关时,重写问题以改进检索效果.- # 让LLM重写问题的提示词
- REWRITE_PROMPT = (
- "查看输⼊并尝试推断潜在的语义意图/含义。\n"
- "这是最初的问题:"
- "\n ------- \n"
- "{question}"
- "\n ------- \n"
- "提出⼀个改进后的问题:"
- )
- # 定义重写节点(问题优化节点,优化用户提出的问题)
- def rewrite_node(state:MessagesState):
- """重新用户原始问题,对用户的问题进行改进"""
- messages = state["messages"]
- # 此时的messages中包含
- # HumanMessage(用户输入的问题)
- # AIMessage(第一次调用LLM的结果,其中包含tool_calls)
- # ToolMessage(工具调用的结果)
- # 现在需要获取到HumanMessage,并调用LLM进行优化
- question = messages[0].conent
- prompt = REWRITE_PROMPT.format(question=question)
- response = model.invoke([HumanMessage(content=prompt)])
- #更新节点状态,把修改后的用户问题,设置为新的用户消息
- return {
- "messages":[HumanMessage(content=response.content)]
- }
该节点将基于相关文档生成最终答案。- # 定义答案节点
- # 定义答案生成的提示词
- GENERATE_PROMPT = (
- "你是负责回答问题的助⼿。 "
- "使⽤以下检索到的上下⽂⽚段来回答问题。 "
- "如果你不知道答案,就说你不知道。 "
- "最多只⽤三句话,回答要简明扼要。\n"
- "Question: {question} \n"
- "Context: {context}"
- )
- def generate_answer(state:MessagesState):
- # 此时的消息中包含[HumanMessage,AIMessage,ToolMessage]
- # 问题+检索结果
- question = state["messages"][0].content #HumanMessage
- context = state["messages"][-1].content #ToolMessage
- prompt = GENERATE_PROMPT.format(question=question,context=context)
- #调用LLM构建AIMessage,返回最终的结果
- return {
- "messages":[model.invoke(HumanMessage(context=prompt))]
- }
根据下图,开始组装"工作流水线"。
添加节点与入口点- # 4.创建图,添加节点、边
- workflow = StateGraph(MessagesState)
- workflow.add_node(generate_query_or_respond) #决策节点
- workflow.add_node("retriever",retriever_node) #检索节点
- workflow.add_node(rewrite_node) #重写问题节点
- workflow.add_node(generate_answer) #生成答案节点
- workflow.add_edge(START,"generate_query_or_respond")
- workflow.add_conditional_edges(
- "generate_query_or_respond",
- tools_condition, #LangGraph提供的函数,检查是否需要调用工具
- {
- "tools":"retriever",
- "__end__":END
- }
- )
- #定义LLM调用后的结构化输出结果
- class GradeDocumnet(BaseModel):
- score:str=Field(description="相关性评分,如果相关则为“yes”,如果不相关则为“no”")
- GRADE_PROMPT = (
- "你是⼀个评分员,评估检索到的⽂档与⽤⼾问题的相关性。 \n "
- "以下是检索到的⽂档: \n\n {context} \n\n"
- "以下是⽤⼾的问题: {question} \n"
- "如果⽂档包含与⽤⼾问题相关的关键字或语义,则将其评为相关。 \n"
- "给出⼀个⼆元分数“yes”或“no”,以表明该⽂档是否与问题相关。"
- )
- #判断检索到的结果是否正确(正确则生成答案,有问题怎重写问题)
- def grade_documents(state:MessagesState)-> Literal["rewrite_node", "generate_answer"]:
- """确定检索到的文档是否与问题相关"""
- #将问题和检索到的文档交给LLM,判断是否相关(yes->rewrite_node,no->generate_answer)
- #需要过滤出用户最新的消息和检索工具调用的结果
- user_messages = filter_messages(state["messages"])
- question = user_messages[-1].content
- tool_message = state["messages"][-1]
- context = tool_message.content
- prompt = GRADE_PROMPT.format(context=context,question=question)
- result = model.with_structured_output(GradeDocumnet).invoke(
- [HumanMessage(content=prompt)]
- ).content
- if result.str=="yes":
- return "generate_answer"
- else:
- return "rewrite_node"
- workflow.add_conditional_edges(
- "retriever",
- grade_documents,
- ["generate_answer","rewrite_node"]
- )
- workflow.add_edge("generate_answer",END)
- workflow.add_edge("rewrite_node","generate_query_or_respond")
- # 5.编译图
- graph = workflow.compile()
- # 执行图
- # 流式输出
- for chunk in graph.stream(
- {
- "messages":[HumanMessage(content="记忆岛这个项目的开发用到了哪些技术?")]
- }
- ):
- print(chunk)
- # 基于LangGraph实现的RAG(检索增强生成)
- from typing import Literal
- from langchain.chat_models import init_chat_model
- from langchain_community.document_loaders import UnstructuredMarkdownLoader
- from langchain_core.messages import HumanMessage, filter_messages
- from langchain_core.tools import create_retriever_tool
- from langchain_core.vectorstores import InMemoryVectorStore
- from langchain_openai import OpenAIEmbeddings
- from langchain_text_splitters import RecursiveCharacterTextSplitter
- from langgraph.constants import START, END
- from langgraph.graph import MessagesState, StateGraph
- from langgraph.prebuilt import ToolNode, tools_condition
- from pydantic import BaseModel, Field
- # 1.准备知识库,并创建检索工具
- # 创建聊天模型与嵌入式模型
- model = init_chat_model("gpt-4o-mini")
- embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
- # 文档列表
- paths =[
- "../Docs/MarkDown/城市展厅项目.md",
- "../Docs/MarkDown/智能PPT导览项目.md",
- "../Docs/MarkDown/记忆岛项目.md"
- ]
- # 文档加载器
- # 得到的一个结果的结构类似:
- # [Document(page_content="文档1内容", metadata={"source": "doc1.md"})]
- docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
- # docs = [
- # [Document(page_content="test1的内容", metadata={"source": "test1.md"})],
- # [Document(page_content="test2的内容", metadata={"source": "test2.md"})]
- # ]
- # 把嵌套列表转换成扁平列表
- docs_list = [item for sublist in docs for item in sublist]
- # docs_list = [
- # Document(page_content="test1的内容", metadata={"source": "test1.md"}),
- # Document(page_content="test2的内容", metadata={"source": "test2.md"})
- # ]
- # 使用分词器对文档进行分割
- text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
- encoding_name="cl100k_base",
- chunk_size=1000,
- chunk_overlap=50
- )
- doc_splits = text_splitter.split_documents(docs_list)
- # 使用嵌入模型将文档转化为向量,使用内存数据库存储
- vector_store = InMemoryVectorStore.from_documents(
- documents=doc_splits,
- embedding=embedding_model
- )
- # 使⽤ LangChain 的预构建 create_retriever_tool 创建检索器⼯具
- retriever = vector_store.as_retriever(search_kwargs={"k": 2})
- retriever_tool = create_retriever_tool(
- retriever,
- "retrieve",
- "搜索并返回有关城市展厅/智能PPT导览/记忆岛项目开发的信息。",
- )
- # 2.定义状态
- # 此处可以自定义消息状态
- # 也可以直接使用LangGraph包中提供的MessagesState
- # class MessageState(TypedDict):
- # #消息列表(AIMessage,ToolMessage,HumanMessage)
- # messages:Annotated[list[AnyMessage],operator.add]
- # 3.定义节点
- # 定义决策节点(AI决策是否需要检索)
- # 调用LLM绑定检索工具的节点,判断是否需要调用检索工具
- def generate_query_or_respond(state:MessagesState):
- """调用模型基于当前的状态生成响应,给定问题,它将决定是否使用工具进行检索,或者是直接给用户返回答案"""
- result = model.bind_tools([retriever_tool]).invoke(state["messages"])
- # result是AIMessage,可能包含tool_calls,也可能不包含
- return {
- "messages":[result]
- }
- # 定义工具节点,调用检索工具
- # 可以实现一个函数,函数中调用工具
- # 也可以直接使用LangGraph提供的ToolNode来生成工具节点
- retriever_node = ToolNode([retriever_tool])
- # 让LLM重写问题的提示词
- REWRITE_PROMPT = (
- "查看输⼊并尝试推断潜在的语义意图/含义。\n"
- "这是最初的问题:"
- "\n ------- \n"
- "{question}"
- "\n ------- \n"
- "提出⼀个改进后的问题:"
- )
- # 定义重写节点(问题优化节点,优化用户提出的问题)
- def rewrite_node(state:MessagesState):
- """重新用户原始问题,对用户的问题进行改进"""
- messages = state["messages"]
- # 此时的messages中包含
- # HumanMessage(用户输入的问题)
- # AIMessage(第一次调用LLM的结果,其中包含tool_calls)
- # ToolMessage(工具调用的结果)
- # 现在需要获取到HumanMessage,并调用LLM进行优化
- question = messages[0].conent
- prompt = REWRITE_PROMPT.format(question=question)
- response = model.invoke([HumanMessage(content=prompt)])
- #更新节点状态,把修改后的用户问题,设置为新的用户消息
- return {
- "messages":[HumanMessage(content=response.content)]
- }
- # 定义答案节点
- # 定义答案生成的提示词
- GENERATE_PROMPT = (
- "你是负责回答问题的助⼿。 "
- "使⽤以下检索到的上下⽂⽚段来回答问题。 "
- "如果你不知道答案,就说你不知道。 "
- "最多只⽤三句话,回答要简明扼要。\n"
- "Question: {question} \n"
- "Context: {context}"
- )
- def generate_answer(state:MessagesState):
- # 此时的消息中包含[HumanMessage,AIMessage,ToolMessage]
- # 问题+检索结果
- question = state["messages"][0].content #HumanMessage
- context = state["messages"][-1].content #ToolMessage
- prompt = GENERATE_PROMPT.format(question=question,context=context)
- #调用LLM构建AIMessage,返回最终的结果
- return {
- "messages":[model.invoke(HumanMessage(context=prompt))]
- }
- # 4.创建图,添加节点、边
- workflow = StateGraph(MessagesState)
- workflow.add_node(generate_query_or_respond) #决策节点
- workflow.add_node("retriever",retriever_node) #检索节点
- workflow.add_node(rewrite_node) #重写问题节点
- workflow.add_node(generate_answer) #生成答案节点
- workflow.add_edge(START,"generate_query_or_respond")
- workflow.add_conditional_edges(
- "generate_query_or_respond",
- tools_condition, #LangGraph提供的函数,检查是否需要调用工具
- {
- "tools":"retriever",
- "__end__":END
- }
- )
- #定义LLM调用后的结构化输出结果
- class GradeDocumnet(BaseModel):
- score:str=Field(description="相关性评分,如果相关则为“yes”,如果不相关则为“no”")
- GRADE_PROMPT = (
- "你是⼀个评分员,评估检索到的⽂档与⽤⼾问题的相关性。 \n "
- "以下是检索到的⽂档: \n\n {context} \n\n"
- "以下是⽤⼾的问题: {question} \n"
- "如果⽂档包含与⽤⼾问题相关的关键字或语义,则将其评为相关。 \n"
- "给出⼀个⼆元分数“yes”或“no”,以表明该⽂档是否与问题相关。"
- )
- #判断检索到的结果是否正确(正确则生成答案,有问题怎重写问题)
- def grade_documents(state:MessagesState)-> Literal["rewrite_node", "generate_answer"]:
- """确定检索到的文档是否与问题相关"""
- #将问题和检索到的文档交给LLM,判断是否相关(yes->rewrite_node,no->generate_answer)
- #需要过滤出用户最新的消息和检索工具调用的结果
- user_messages = filter_messages(state["messages"])
- question = user_messages[-1].content
- tool_message = state["messages"][-1]
- context = tool_message.content
- prompt = GRADE_PROMPT.format(context=context,question=question)
- result = model.with_structured_output(GradeDocumnet).invoke(
- [HumanMessage(content=prompt)]
- ).content
- if result.str=="yes":
- return "generate_answer"
- else:
- return "rewrite_node"
- workflow.add_conditional_edges(
- "retriever",
- grade_documents,
- ["generate_answer","rewrite_node"]
- )
- workflow.add_edge("generate_answer",END)
- workflow.add_edge("rewrite_node","generate_query_or_respond")
- # 5.编译图
- graph = workflow.compile()
- # 执行图
- # 流式输出
- for chunk in graph.stream(
- {
- "messages":[HumanMessage(content="记忆岛这个项目的开发用到了哪些技术?")]
- }
- ):
- print(chunk)
|






























 广告
广告