1、Milvus向量数据库是什么?
Milvus 是一个开源的、高性能、高扩展性的向量数据库,专门用于处理和检索高维向量数据。它适用于相似性搜索(Approximate Nearest Neighbor Search,ANN),特别适合AI、推荐系统、计算机视觉、自然语言处理(NLP)等领域。
Zilliz 采用 Milvus 作为其开源高性能、高扩展性向量数据库的名称,该数据库可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。它既是开源软件,也是云服务。
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅长构建大规模系统和优化硬件感知代码。核心贡献者包括来自 Zilliz、ARM、英伟达、AMD、英特尔、Meta、IBM、Salesforce、阿里巴巴和微软的专业人士。
Quickstart | Milvus Documentation
2、非结构化数据、Embeddings 和 Milvus
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
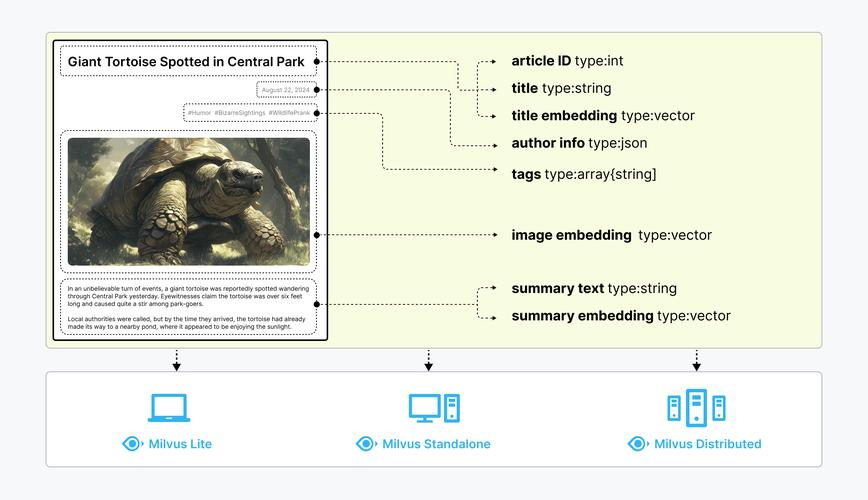
非结构化数据、Embeddings 和 Milvus
3、Milvus架构
Milvus 主要由以下组件组成:
Coordinator(协调器):管理元数据、查询和数据分片。
Proxy(代理):处理 API 请求并转发给计算节点。
QueryNode(查询节点):执行 ANN 查询,返回最近邻数据。
DataNode(数据节点):存储和管理向量数据。
IndexNode(索引节点):构建和存储索引以加速查询。
MetaStore(元数据存储):使用 etcd 存储元数据。
Storage(存储层):使用 MinIO/S3 存储向量数据和索引。
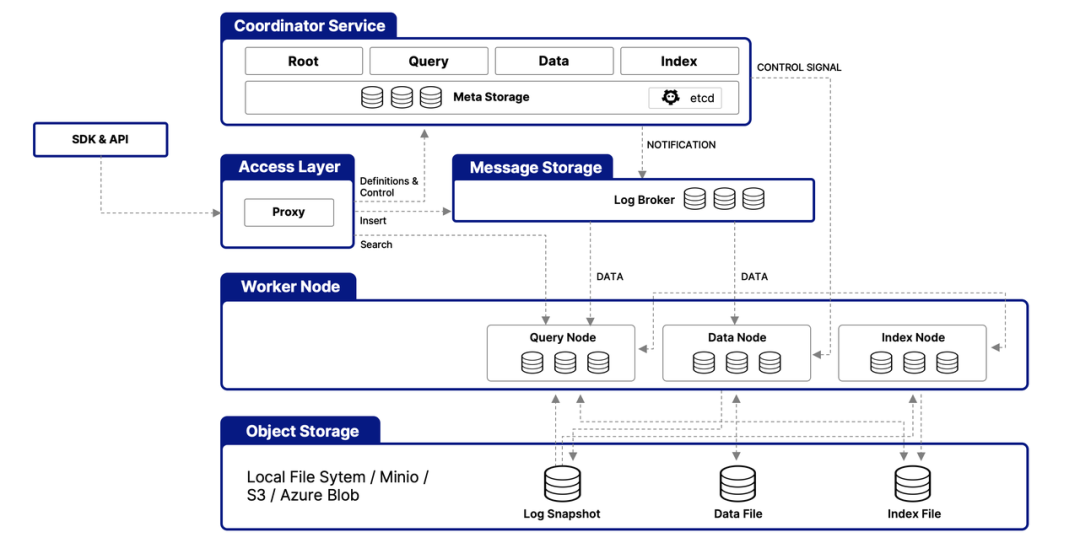
highly-decoupled-architecture
Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展。Milvus 本身是完全无状态的,因此可以借助 Kubernetes 或公共云轻松扩展。此外,Milvus 的各个组件都有很好的解耦,其中最关键的三项任务--搜索、数据插入和索引/压实--被设计为易于并行化的流程,复杂的逻辑被分离出来。这确保了相应的查询节点、数据节点和索引节点可以独立地向上和向下扩展,从而优化了性能和成本效率。
4、Milvus的基本概念:collection、schema、Fields
Milvus 是一个专门用于向量相似度检索的数据库系统。在 Milvus 中,collection 、 schema和Fields 是三个核心概念,它们对于数据的组织和管理至关重要。
(1)Collection
Collection 在 Milvus 中可以理解为数据的集合或者表。每个 collection 都是由一系列具有相同结构(由 schema 定义)的数据记录组成。这些记录通常是高维向量,但也可以包含一些标量字段来辅助过滤或排序。
你可以把 collection 看作是存储相似类型数据的地方。例如,在图像搜索应用中,所有图像特征向量可能会被存储在一个 collection 中,而文本特征向量则可能被存储在另一个 collection 中。
(2)Schema
Schema 定义了一个 collection 的结构,包括向量字段和其他标量字段的信息。具体来说,schema 包含了字段名、字段类型以及是否为主键等信息。在 Milvus 中,每个 collection 必须有一个唯一的 schema。对于向量字段,schema 还会指定向量的维度,这是指向量有多少个元素。对于标量字段,可以根据需要定义不同的数据类型,比如整型、浮点型、字符串等。通过定义 schema,用户可以在创建 collection 时指定数据如何组织,这有助于确保数据的一致性和有效性。
在使用 Milvus 时,首先需要根据你的数据特点设计合适的 schema,然后基于这个 schema 创建 collection 来存储和管理数据。这样做不仅有助于保持数据的组织性,还能够提高查询效率,特别是在处理大规模向量数据时尤为重要。
(3)Fields
在 Milvus 数据库中,字段(Fields)是构成 collection 的基本单位。每个字段都有其特定的数据类型和作用,主要分为向量字段和标量字段两大类。
以下是关于 Milvus 数据库字段的一些关键概念:
字段类型
向量字段:这是 Milvus 中最重要的字段类型,用于存储高维向量数据。向量字段是进行相似度搜索的基础。定义向量字段时,必须指定向量的维度,即向量中元素的数量。
标量字段:除了向量字段之外,Milvus 也支持标量字段来存储额外的信息。这些信息可以用来过滤、排序等操作。标量字段可以有多种数据类型,包括但不限于整型(int32, int64)、浮点型(float, double)、布尔型(bool)、字符串型(varchar)等。
字段属性
主键字段:在 Milvus 2.x 版本中,collection 可以拥有一个主键字段。这个字段对于每条记录都是唯一的,并且自动索引,主要用于快速定位某一条具体的记录。
索引字段:虽然所有向量字段默认都会被索引,但在某些情况下,你可能还需要对标量字段创建索引来加速查询速度。
定义 Fields
在创建 collection 之前,需要先定义 schema,而在 schema 中就需要明确指定各个字段的名字、类型以及是否为主键等信息。例如,在 Python 中使用 pymilvus 库时,可以通过以下方式定义一个包含向量字段和标量字段的 schema:- from pymilvus import FieldSchema, CollectionSchema, DataType
- # 定义字段
- field1 = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True)
- field2 = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128) # 假设向量维度为128
- field3 = FieldSchema(name="age", dtype=DataType.INT32)
- # 创建集合schema
- schema = CollectionSchema(fields=[field1, field2, field3], description="My collection")
通过合理设计和使用字段,可以使你在 Milvus 中更高效地管理和检索大规模向量数据。
5、Milvus部署模式
(1)Milvus 提供三种部署模式,涵盖各种数据规模
Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 笔记本电脑中进行快速原型开发,或在资源有限的边缘设备上运行。
Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。
Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。该架构可确保关键组件的冗余。
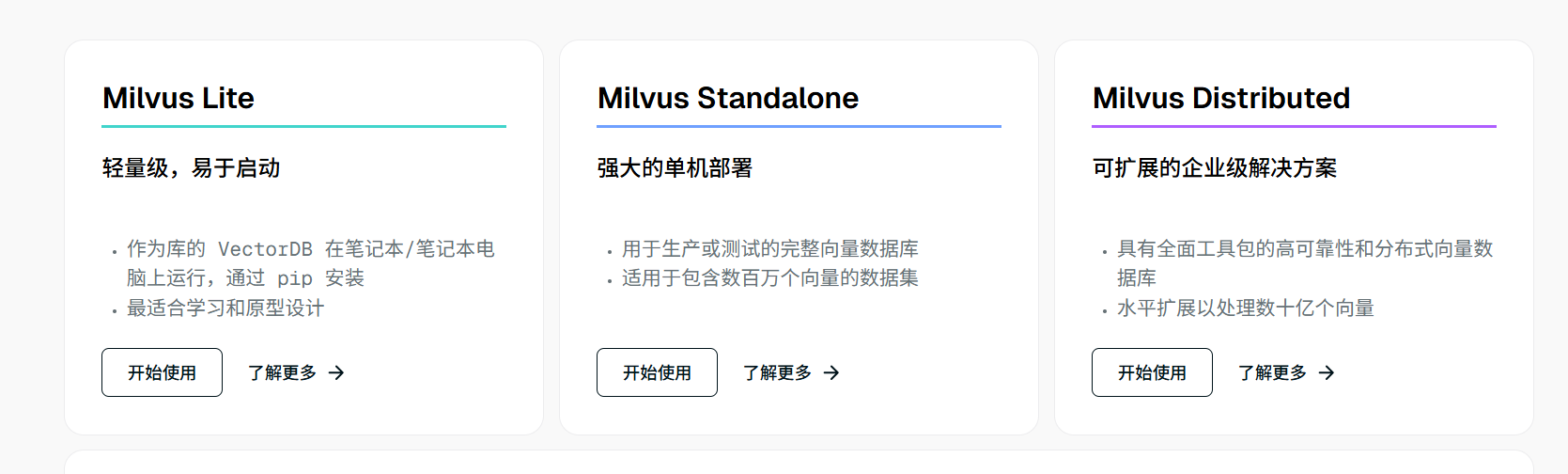
(2)根据你的项目数据集规模,选择适合你的部署方式
Milvus Lite建议用于较小的数据集,多达几百万个向量。
Milvus Standalone适用于中型数据集,可扩展至 1 亿向量。
Milvus Distributed 专为大规模部署而设计,能够处理从一亿到数百亿向量的数据集。
(3)Milvus Standalone 单机版部署方式的硬件配置要求

6、Milvus 支持的搜索类型
Milvus 支持各种类型的搜索功能,以满足不同用例的需求:
ANN 搜索:查找最接近查询向量的前 K 个向量。
过滤搜索:在指定的过滤条件下执行 ANN 搜索。
范围搜索:查找查询向量指定半径范围内的向量。
混合搜索:基于多个向量场进行 ANN 搜索。
全文搜索:基于 BM25 的全文搜索。
Rerankers:根据附加标准或辅助算法调整搜索结果顺序,完善初始 ANN 搜索结果。
获取:根据主键检索数据。
查询: 使用特定表达式检索数据。
7、为什么 Milvus 这么快?
Milvus 运行比较快的原因有以下几个:
硬件感知优化:为了让 Milvus 适应各种硬件环境,Zilliz团队专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。
高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
C++ 搜索引擎:向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 将 C++ 用于这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
8、Win10在 Docker 中运行 Milvus
本地Win10电脑使用 Milvus Standalone 单机版部署方式。Milvus 提供了一个安装脚本,可将其安装为 Docker 容器。在 Microsoft Windows 上安装 Docker Desktop 后,就可以在管理员模式下通过 PowerShell 或 Windows Command Prompt 以及 WSL 2 访问 Docker CLI。
(1)安装 Docker Desktop
点击下载软件安装 https://www.docker.com/get-started/
安装之后,需要重启电脑,并且电脑会进行 Linux 子系统更新才能正常启动,此过程可能会比较慢。安装 Windows Subsystem for Linux 2 (WSL 2):通常不需要单独安装,安装 Docker Desktop 时会自动安装。
Docker镜像仓库配置:- {
- "builder": {
- "gc": {
- "defaultKeepStorage": "20GB",
- "enabled": true
- }
- },
- "experimental": false,
- "registry-mirrors": [
- "https://registry.docker-cn.com",
- "https://docker.hpcloud.cloud",
- "https://docker.m.daocloud.io",
- "https://docker.unsee.tech",
- "https://docker.1panel.live",
- "http://mirrors.ustc.edu.cn",
- "https://docker.chenby.cn",
- "http://mirror.azure.cn",
- "https://dockerpull.org",
- "https://dockerhub.icu",
- "https://hub.rat.dev",
- "https://proxy.1panel.live",
- "https://docker.1panel.top",
- "https://docker.m.daocloud.io",
- "https://docker.1ms.run",
- "https://docker.ketches.cn"
- ]
- }
在管理员模式下右击并选择以管理员身份运行,打开 Docker Desktop。
下载安装脚本并将其保存为standalone.bat 。- C:\>Invoke-WebRequest https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat -OutFile standalone.bat
- 运行下载的脚本,将 Milvus 作为 Docker 容器启动。
- C:\>standalone.bat start
- Wait for Milvus starting...
- Start successfully.
- To change the default Milvus configuration, edit user.yaml and restart the service.
名为Milvus-standalone的 docker 容器已在19530 端口启动。
嵌入式 etcd 与 Milvus 安装在同一个容器中,服务端口为2379。其配置文件被映射到当前文件夹中的embedEtcd.yaml。
Milvus 数据卷映射到当前文件夹中的volumes/milvus。
可以使用以下命令管理 Milvus 容器和存储的数据。- # Stop Milvus
- C:\>standalone.bat stop
- Stop successfully.
- # Delete Milvus container
- C:\>standalone.bat delete
- Delete Milvus container successfully. # Container has been removed.
- Delete successfully. # Data has been removed.
(3)安装 UI 客户端
Milvus 服务安装成功之后,可以按照一个 UI 客户端连接 Milvus 服务,使用官方提供的客户端 attu:https://github.com/zilliztech/attu
具体安装步骤如下:
1.访问下载安装包(attu-Setup-2.4.12.exe)地址:https://github.com/zilliztech/attu/releases/tag/v2.4.12
2.解压并安装 attu。
安装成功之后连接本地 Milvus 服务,如下图所示:
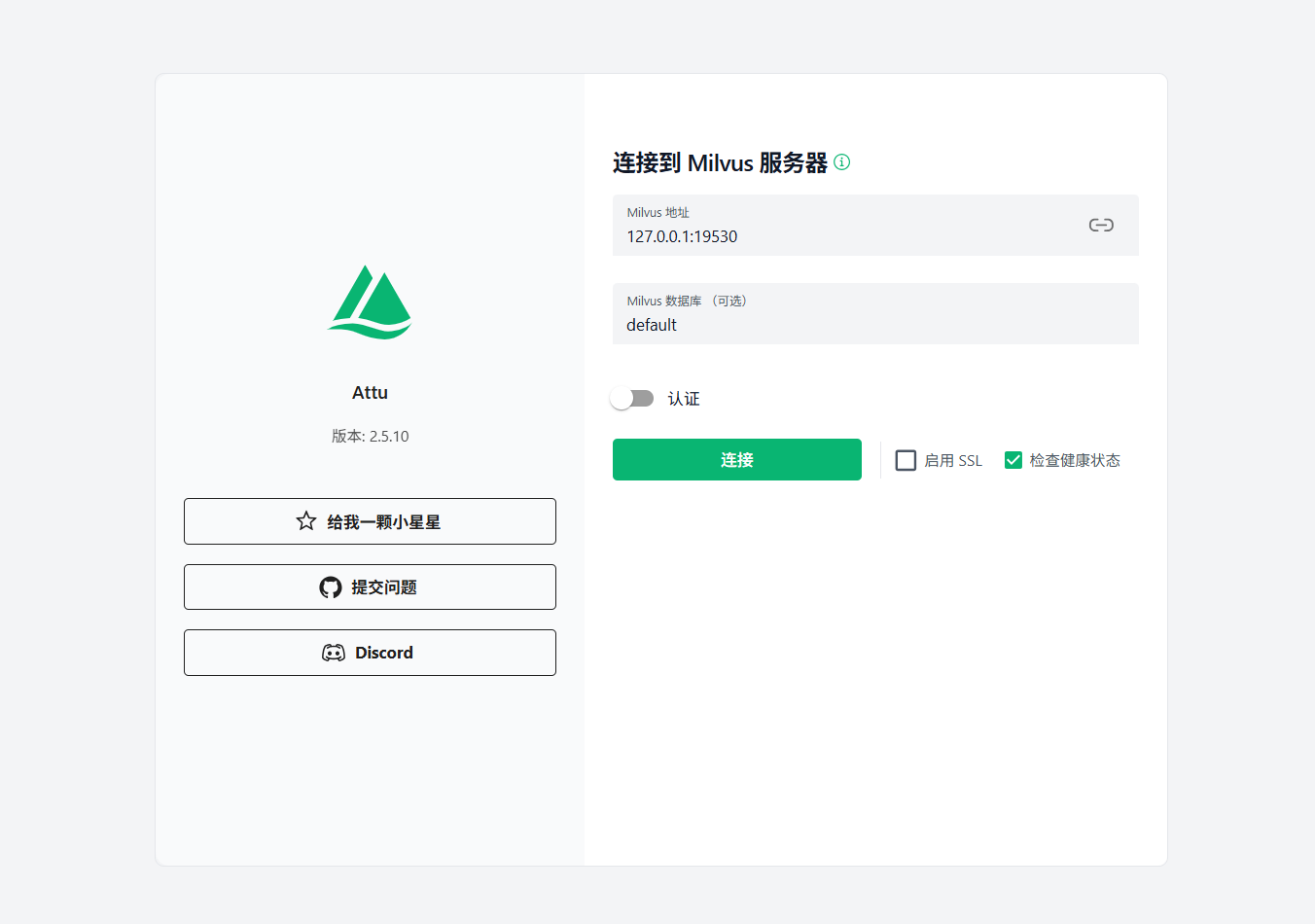
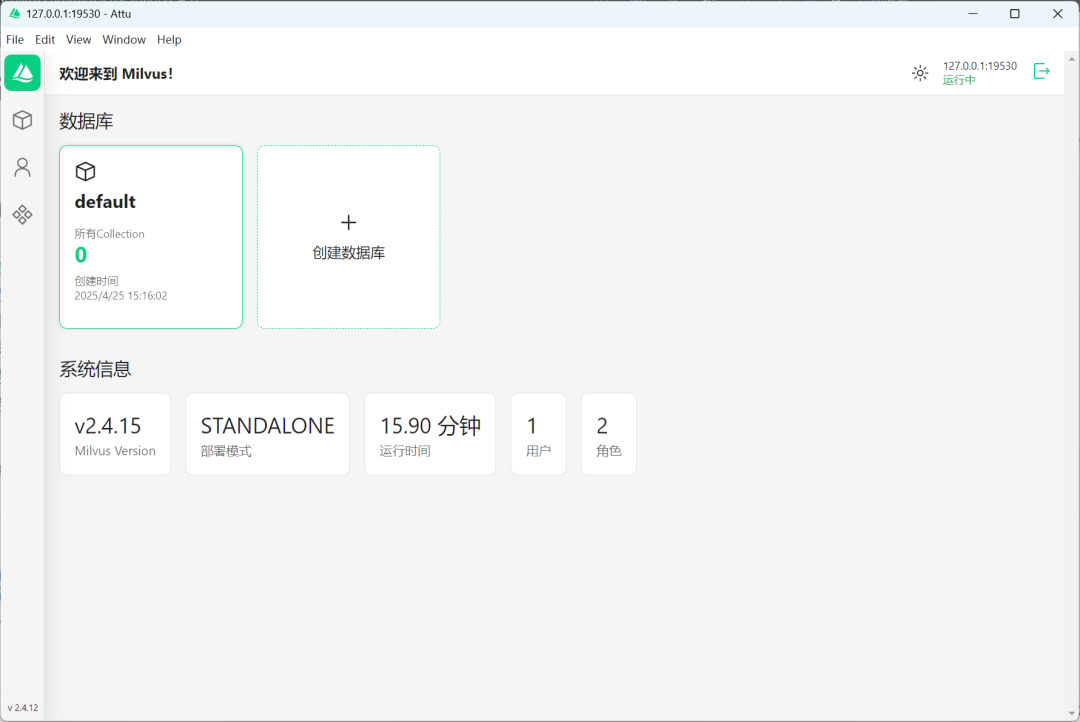
总结:Milvus 作为开源高性能向量数据库的代表,安装完成后就可以用它加上 Spring AI 或 LangChain4j 来实现 RAG 知识库功能。
参考链接:
在window11部署Milvus向量数据库_win11在docker desktop安装milvus-CSDN博客
Quickstart | Milvus Documentation
最火向量数据库Milvus安装使用一条龙!
开源向量数据库Milvus简介
milvus 三种部署方式说明 |

























 广告
广告