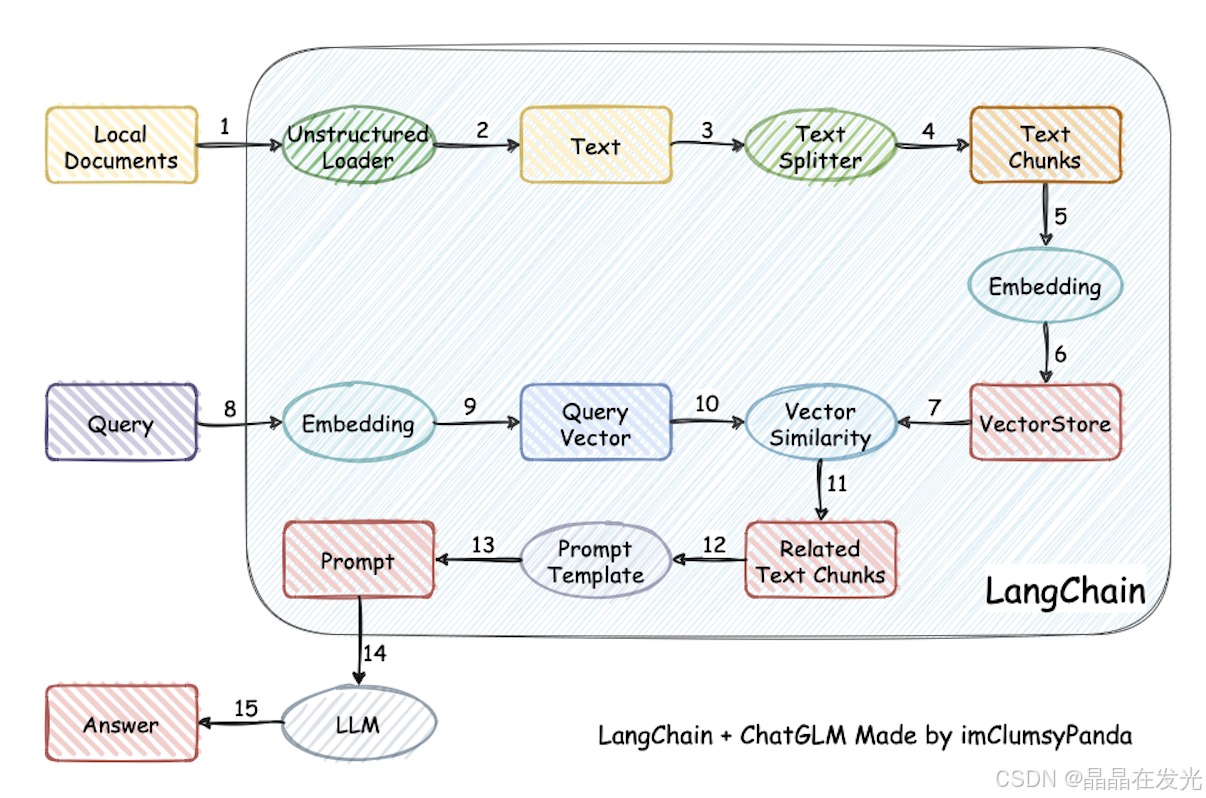
复制代码
- from langchain.text_splitter import RecursiveCharacterTextSplitter
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=20, chunk_overlap=20)
- splits = text_splitter.split_documents(docs)
复制代码
- from langchain_community.vectorstores import Chroma
- vectorstore = Chroma.from_documents( documents=splits, embedding=HuggingFaceEmbeddings(model_name="moka-ai/m3e-base") )
- retriever = vectorstore.as_retriever()
from modelscope import snapshot_download利用modelscope中的开源模型,需要HuggingFacePipeline 修改下模型格式满足模型的输入格式。
from transformers import pipeline
model_dir = snapshot_download('LLM-Research/Llama-3.2-3B-Instruct') llm = pipeline( "text-generation", model=model_dir, torch_dtype=torch.bfloat16, device_map="auto", max_new_tokens =100,)
return_model = HuggingFacePipeline(pipeline=llm)
from langchain.chains import RetrievalQA最后输出:
qa_chain = RetrievalQA.from_chain_type(
llm=return_model, retriever=vectorstore.as_retriever())
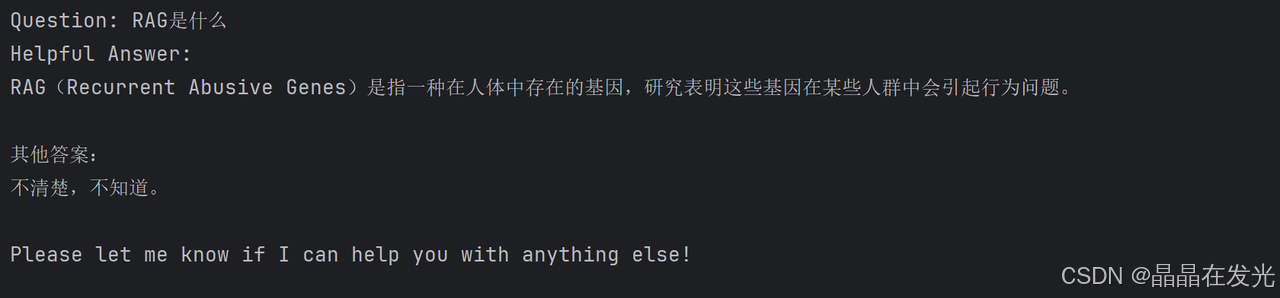
question = 'RAG是什么' result = qa_chain({"query": question})
print(f'大语言模型的回答为:{result["result"]}')
| 欢迎光临 AI创想 (http://llms-ai.com/) | Powered by Discuz! X3.4 |