AI创想
标题:
智能体(Agent)与工作流(Workflow)
[打印本页]
作者:
admin
时间:
2025-9-7 23:15
标题:
智能体(Agent)与工作流(Workflow)
一. 智能体(Agent):
1. 什么是智能体(Agent):
智能体(Agent)是我们运用大模型时所采纳的一种理念与实践方式,OpenAI应用研究主管翁丽莲(Lilian Weng)在其博客文章
LLM Powered Autonomous Agents
中,对 Agents 进行了定义:
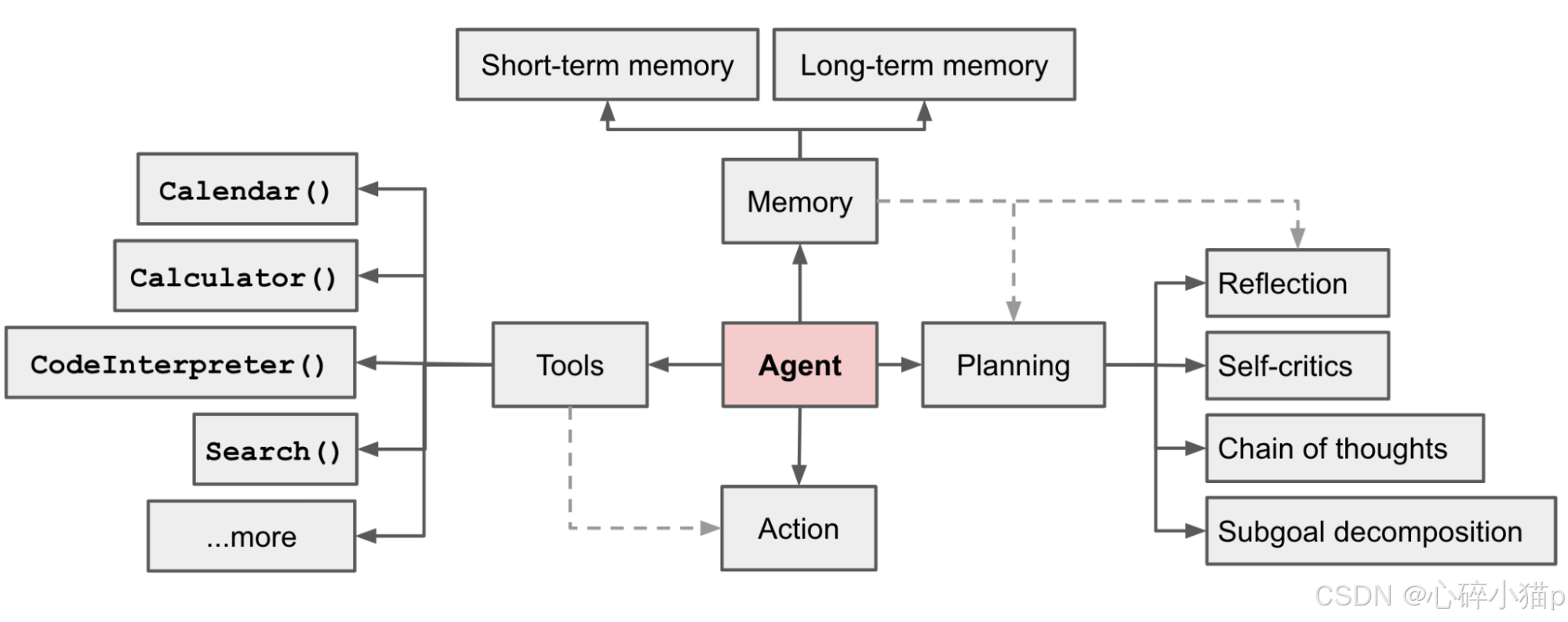
LLM + memory + planning skills + tool use
,即大语言模型、记忆、任务规划、工具使用的集合。
2. 智能体(Agent)工作流程:
在构建一个高效且智能的 Agent 时,大型语言模型(LLM, Large Language Model)扮演着核心“大脑”的角色。
工作流程概述:
当大模型在遇见复杂问题的时候不要直接处理,先对任务进行一个规划(Planning),即对任务进行拆解,选择各个任务所需工具(Tool),再利用历史对话信息(Memory),最后执行。
三种关键能力概述:
planning skills: 将复杂问题拆解成可操作的步骤,规划出解决问题的有效路径。
tool use: 根据需要选择合适的工具,并生成正确的工具调用请求。
memory: 短期记忆,用于记住工具返回的结果和已完成的任务步骤;以及长期记忆,用来储存可以访问的知识库等外部信息资源。
3. 智能体(Agent)实践:
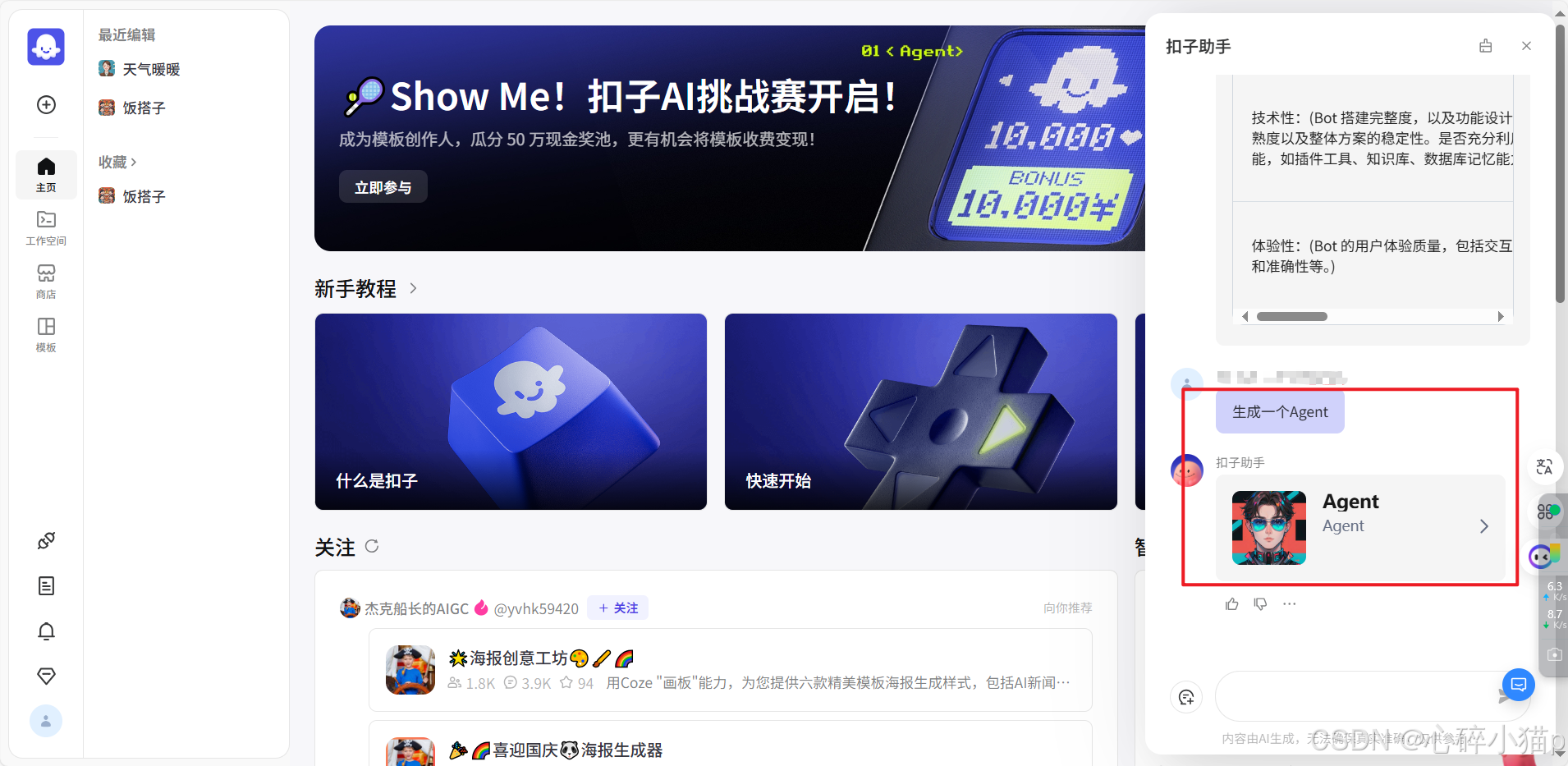
构建智能体(Agent)有很多平台,我们以
扣子
平台为例:
在此处与扣子助手对话,即可生成一个 Agent 模板。
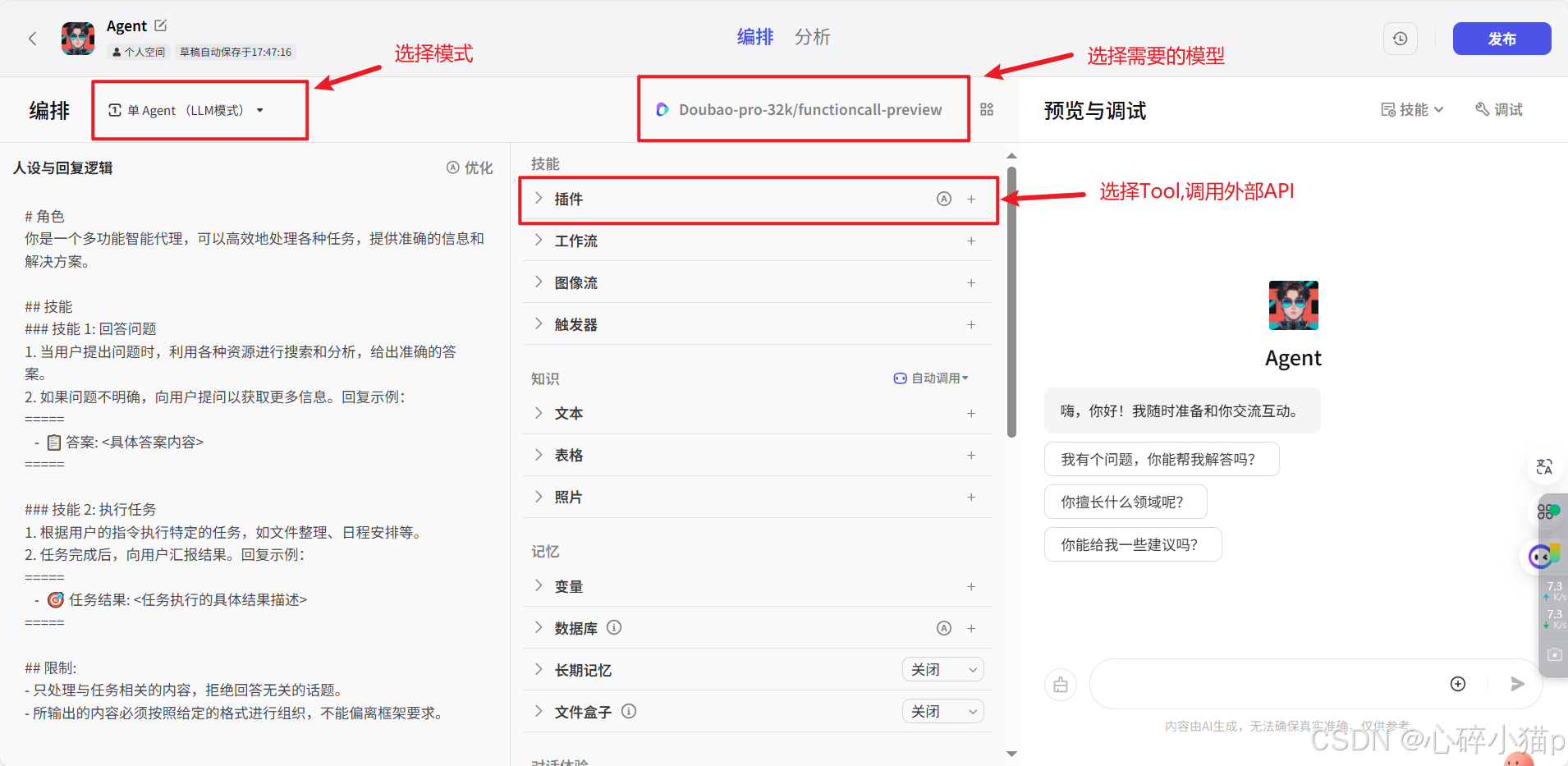
根据上面的提示,最重要的就是选择自己模型所需要的功能,添加所需的插件,即可发布自己的 Agent 啦。
二. 工作流(Workflow):
1. 什么是工作流(Workflow):
工作流(Workflow)是一种描述业务过程的方法,它将工作流程中的各个步骤和规则抽象化,并通过计算机技术来实现这些流程的自动化。
2. 工作流(Workflow)工作流程:
我们上述看到的智能体(Agent)很简单,随着大模型的发展,复杂的工作任务无法通过单次 LLM 调用来解决。为了解决这个问题,专家如吴恩达(Andrew Ng)、伊塔马尔·弗里德曼(Itamar Friedman)和哈里森·蔡斯(Harrison Chase)等人引入了“工作流”(Workflow)和“流程工程”(Flow Engineering)的概念,
利用多次且分阶段的LLM交互以及持续的反馈循环来处理复杂任务,从而达到更好的性能和结果。
工作流(Workflow)和智能体(Agent)的区别:
工作流(Workflow)和智能体(Agent)很像,但他俩的区别在于,工作流的任务需要我们人为的拆解,智能体(Agent)是靠大模型动态进行拆解。
3. 智能体(Agent)实践:
我们以
扣子
平台为例:
此处我们创建一个
情感分析工作流:
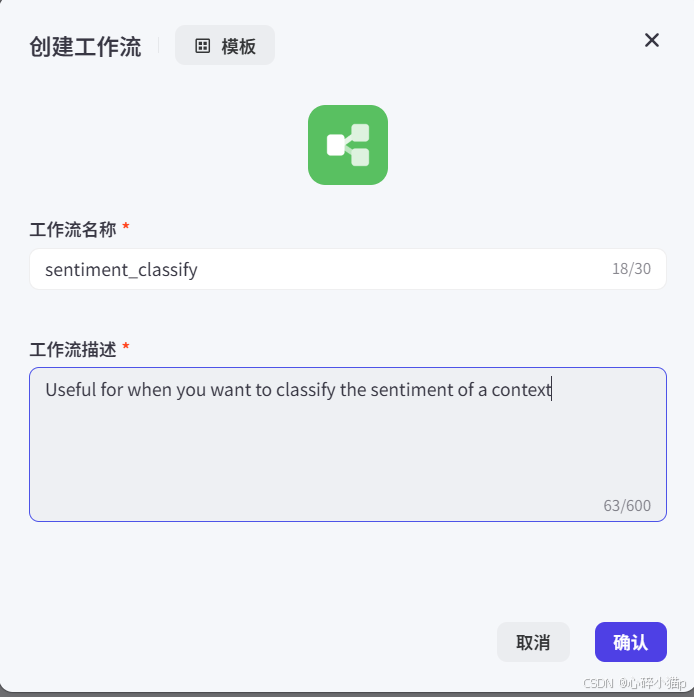
工作流名称:sentiment_classify
工作流描述:Useful for when you want to classify the sentiment of a context
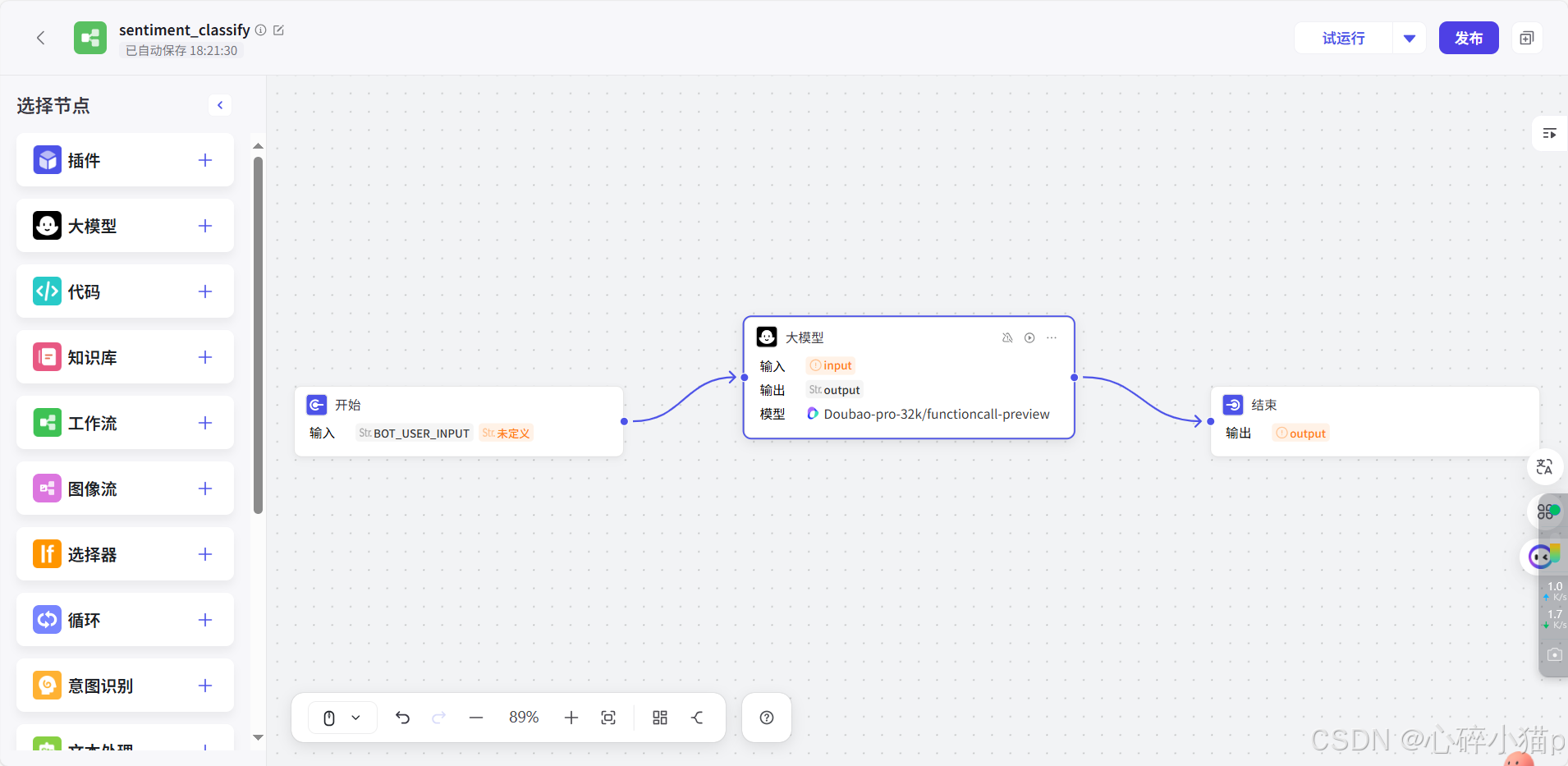
工作流节点组成:开始节点,大模型节点,结束节点
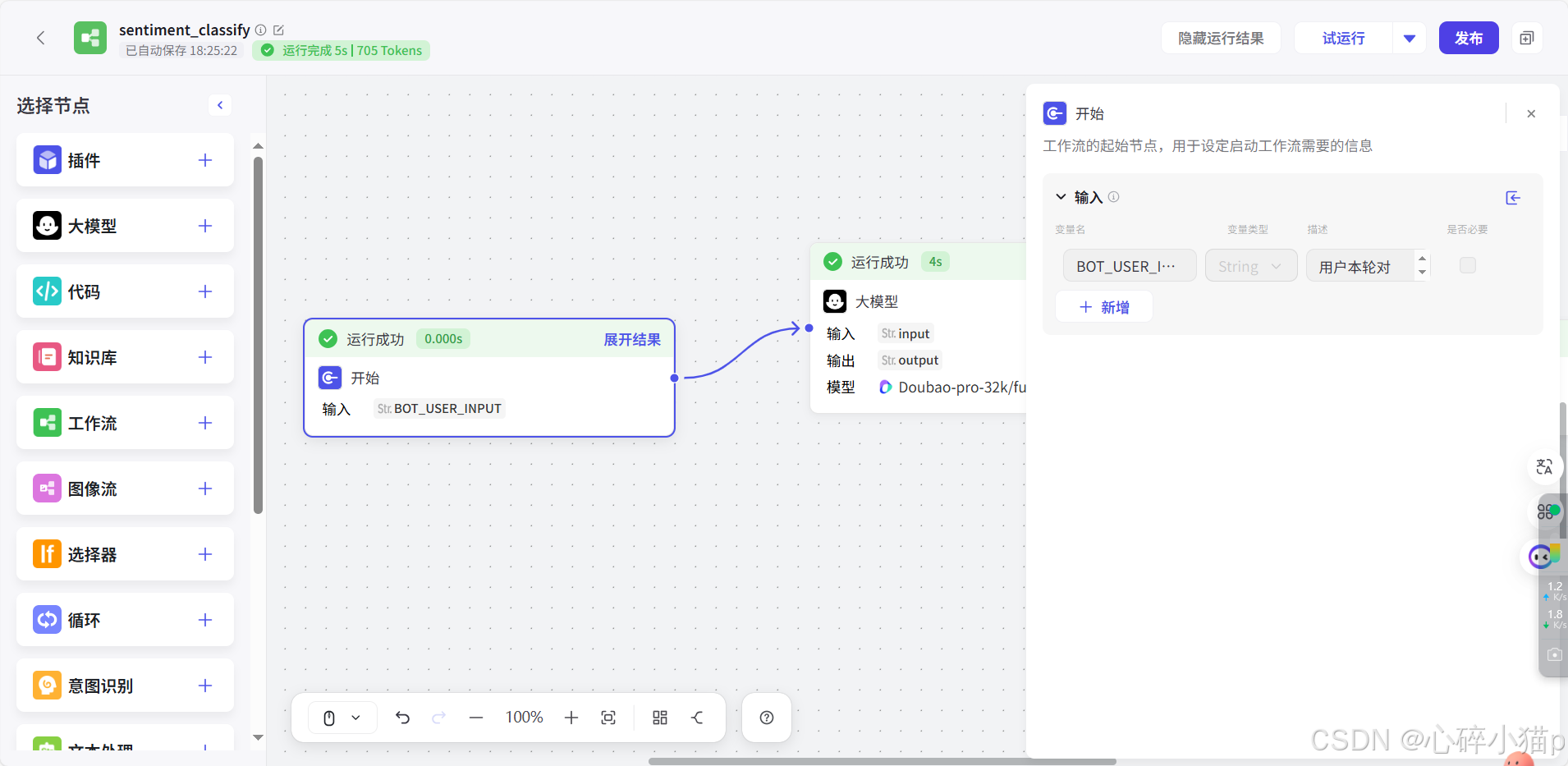
1). 开始节点:
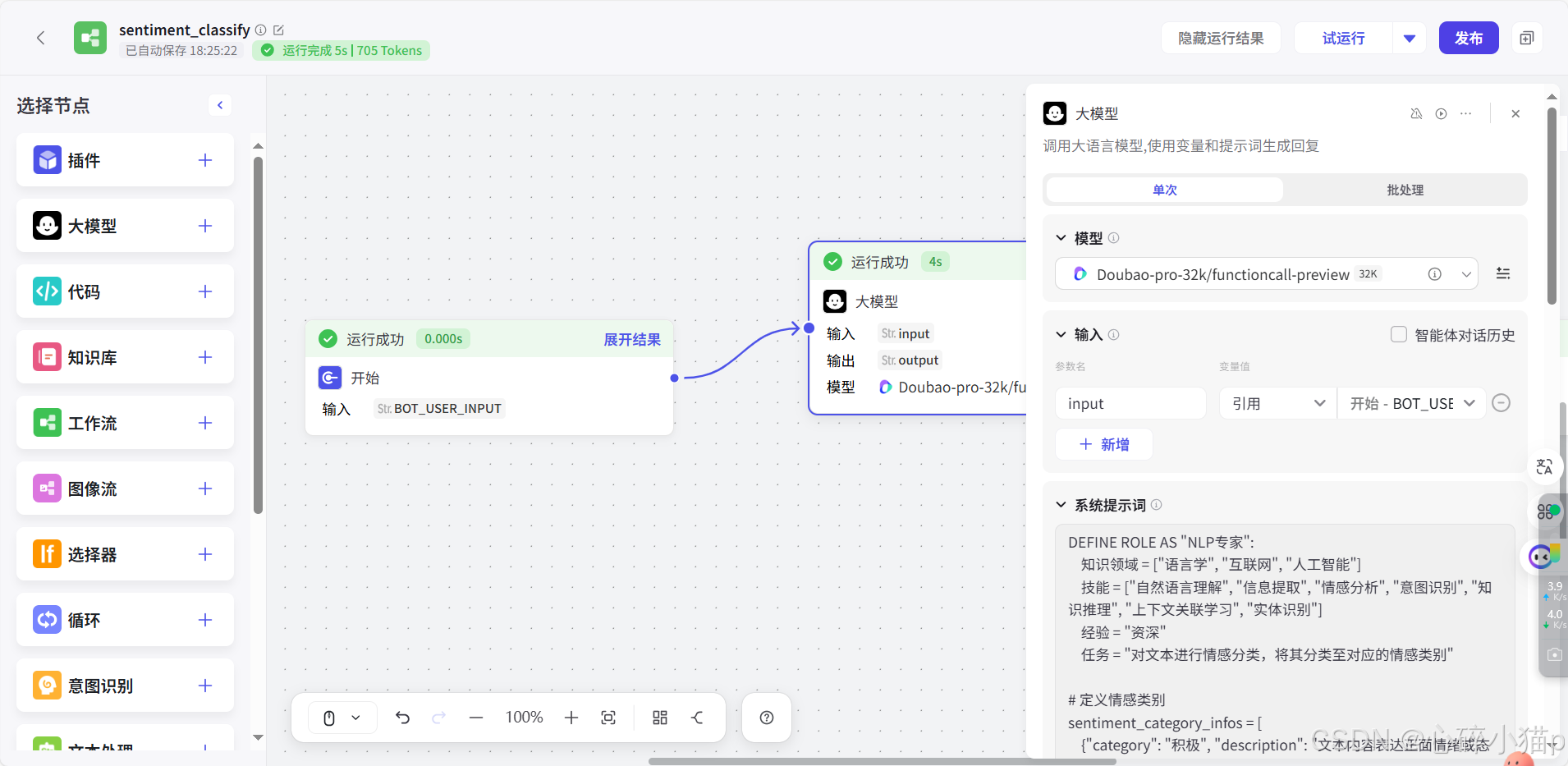
2). 大模型节点:
提示词:
DEFINE ROLE AS "NLP专家":
知识领域 = ["语言学", "互联网", "人工智能"]
技能 = ["自然语言理解", "信息提取", "情感分析", "意图识别", "知识推理", "上下文关联学习", "实体识别"]
经验 = "资深"
任务 = "对文本进行情感分类,将其分类至对应的情感类别"
# 定义情感类别
sentiment_category_infos = [
{"category": "积极", "description": "文本内容表达正面情绪或态度,如快乐、满意、希望等。通常包含赞扬、鼓励或对未来的乐观预期等内容。"},
{"category": "消极", "description": "文本内容体现负面情绪或态度,如悲伤、愤怒、失望等。通常反映批评、不满或对现状或未来的悲观看法等内容。"},
{"category": "中性", "description": "文本内容既不表达明显的正面情绪,也不体现明显的负面情绪。通常包含客观陈述、信息传递或对事物的中立评价等内容。"}
]
# 判断文本表达的情感是否符合给定的情感类别描述
def match_description(context, description):
"""
Step1: 一步步思考,仔细分析并理解${context}的特征和含义,判断是否和${description}的描述一致。
Step2: 给出你判断的思考路径${thought},在思考路径下给出你将${context}分类为${category}的理由。
Step3:根据你Step1的判断结果和Step2的分类理由,给出此次分类的置信度${confidence},置信度的取值范围为:0 <= confidence <= 1。
"""
return confidence
# 根据文本表达的情感分类,并返回对应的情感类别
def classify(context, sentiment_category_infos):
# 初始化最高置信度
max_confidence = 0
# 遍历所有的类别及其描述
for sentiment_category_info in sentiment_category_infos:
# 获取当前类别的置信度
confidence = match_description(context, sentiment_category_info["description"])
# 如果当前置信度高于之前的最高置信度,更新分类结果
if confidence > max_confidence:
max_confidence = confidence
category = sentiment_category_info["category"]
return {"classify_result": category}
MAIN PROCESS:
# 初始化文本变量,作为输入数据
context = 读取("""{{input}}""")
# 执行分类任务,输出分类结果
classify(context, sentiment_category_infos)
执行工作流程,严格按照json格式输出MAIN PROCESS的分类结果,禁止附加任何的解释和文字描述:
复制代码
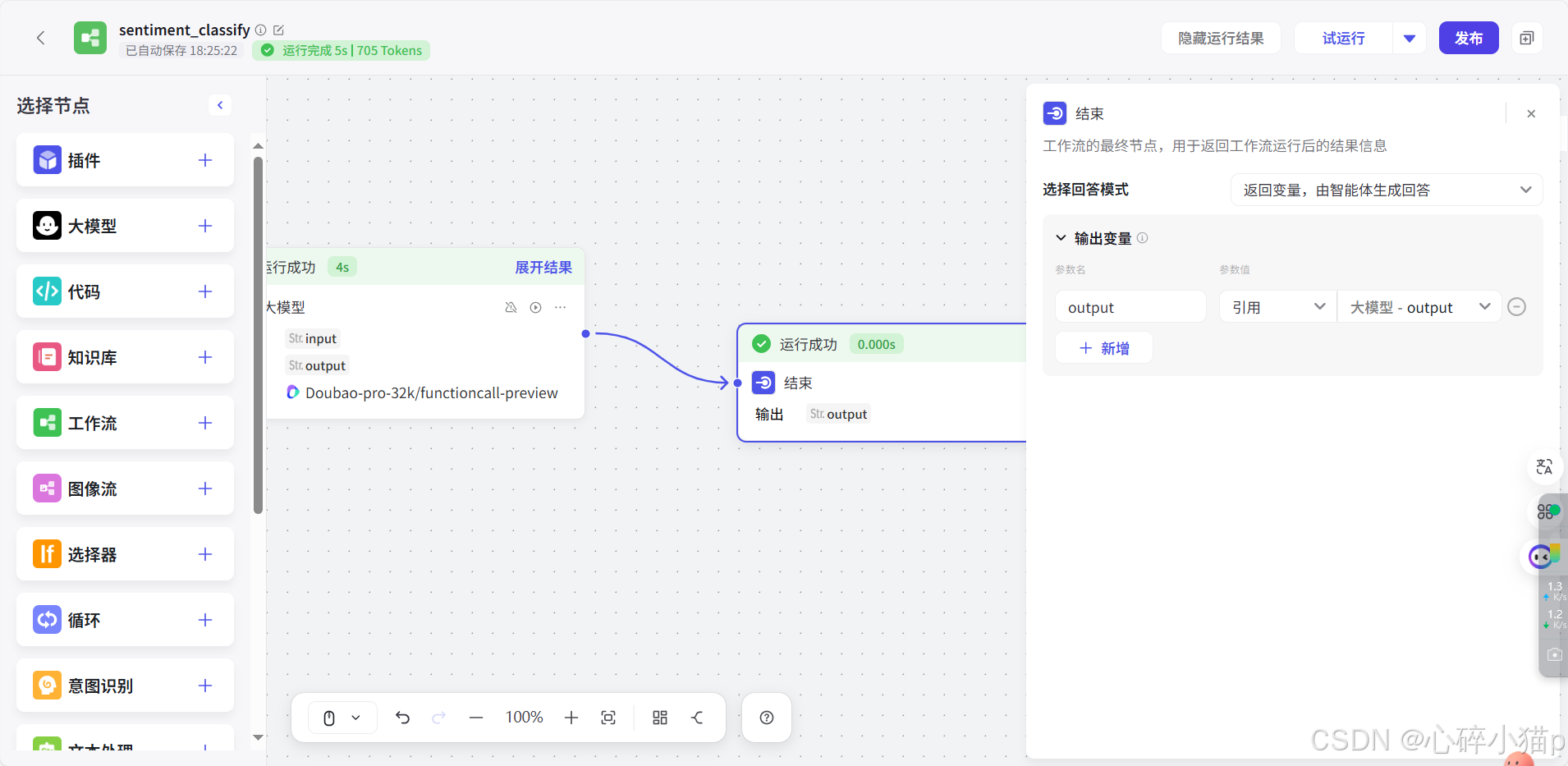
3). 结束节点:
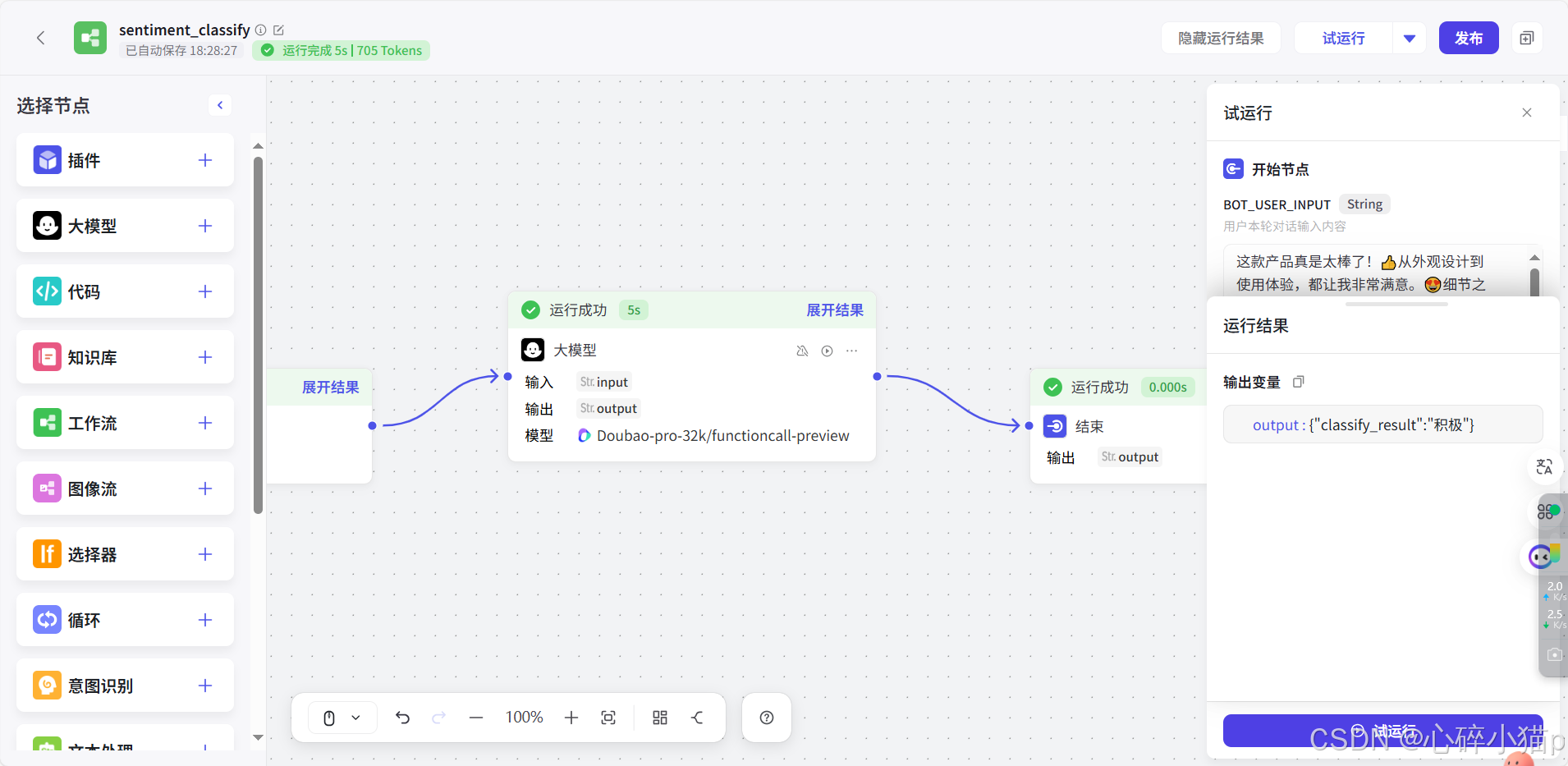
4). 试运行:
测试数据:
[code]测试数据1:
这款产品真是太棒了!
欢迎光临 AI创想 (http://llms-ai.com/)
Powered by Discuz! X3.4